语音活动检测(VAD)
概述
在语音活动检测(VAD)中,有多种模型可供选择,每种模型都有其独特的特点和应用场景。
Webrtc-VAD 是一种广泛应用的语音活动检测模型,它基于语音信号的能量和过零率等特征进行检测。SileroVAD 则采用了深度学习技术,通过对大量语音数据的学习,能够更准确地检测语音活动。FSMN-VAD 结合了前馈序列记忆网络,在处理长语音序列时表现出色。
这些模型在不同的环境和应用中都发挥着重要作用。例如,在电话会议中,Webrtc-VAD 可以有效地过滤背景噪声,提高语音质量;在智能语音助手等场景中,SileroVAD 和 FSMN-VAD 能够更准确地识别用户的语音指令。
未来,随着技术的不断发展,语音活动检测模型将不断改进和创新,为语音通信和交互提供更好的支持。





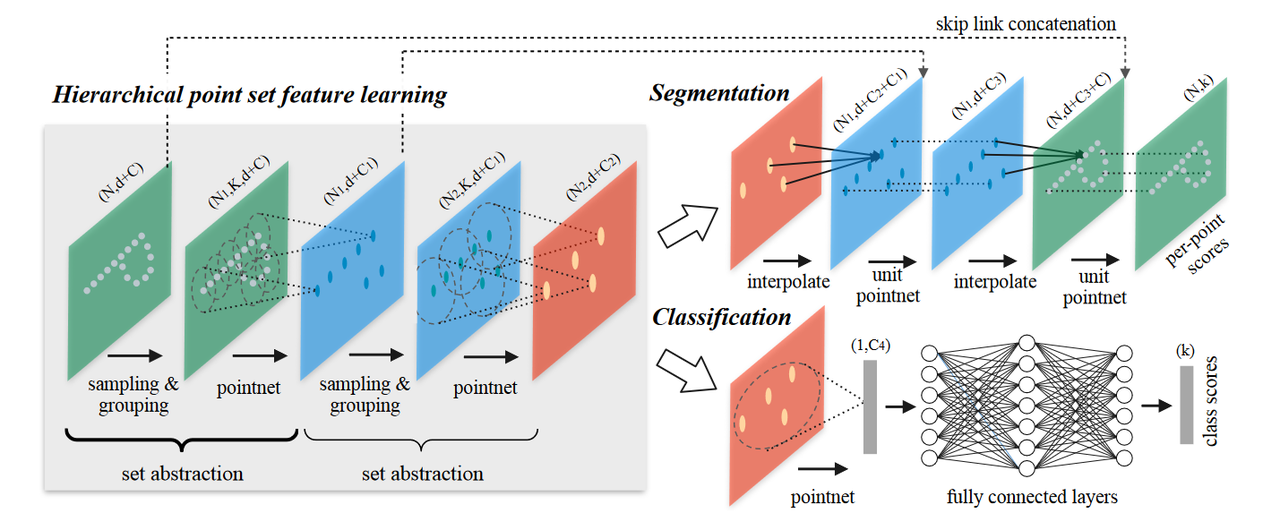
 作者通过分析两阶段网络各个部分耗时情况,发现SA层对于提取点得特征是必要的,但FP和细化模块确实限制了基于点的方法的效率。
作者通过分析两阶段网络各个部分耗时情况,发现SA层对于提取点得特征是必要的,但FP和细化模块确实限制了基于点的方法的效率。