KV Cache管理-llama.cpp
概述
llama.cpp中的KV Cache管理主要涉及Buffer的分配和管理。其中,Buffer采用静态分配的方式,初始时分配上下文大小的Buffer。当序列长度超出设定的上下文时,一种方式通过删除位置相对较远的KV Cache来释放一部分Cache空间,只保留相对较新的KV Cache;另一种是在模型上下文固定的情况下,通过压缩位置嵌入位置信息,实现更长上下文的支持。

KV Cache Init
llama_kv_cache_init函数实现了KV Cache的Buffer的分配和初始化,并根据模型架构不同,使用不同的数据类型保存缓存数据,其中Mamba结构的模型使用 FP32 类型保存,其它架构默认使用 FP16 类型保存。
llama_kv_cache对象初始化
如下代码所示,cells 容器的大小初始化为 上下文的大小,k_l 和 v_l 容器大小初始化为模型的层数,用于存储每层KV向量的数据。
1 | cache.has_shift = false; |
cache对象里对应的数据结构如下:
1 | // ring-buffer of cached KV data |
1 | struct llama_kv_cell { |
上述数据结构图形化表示如下:
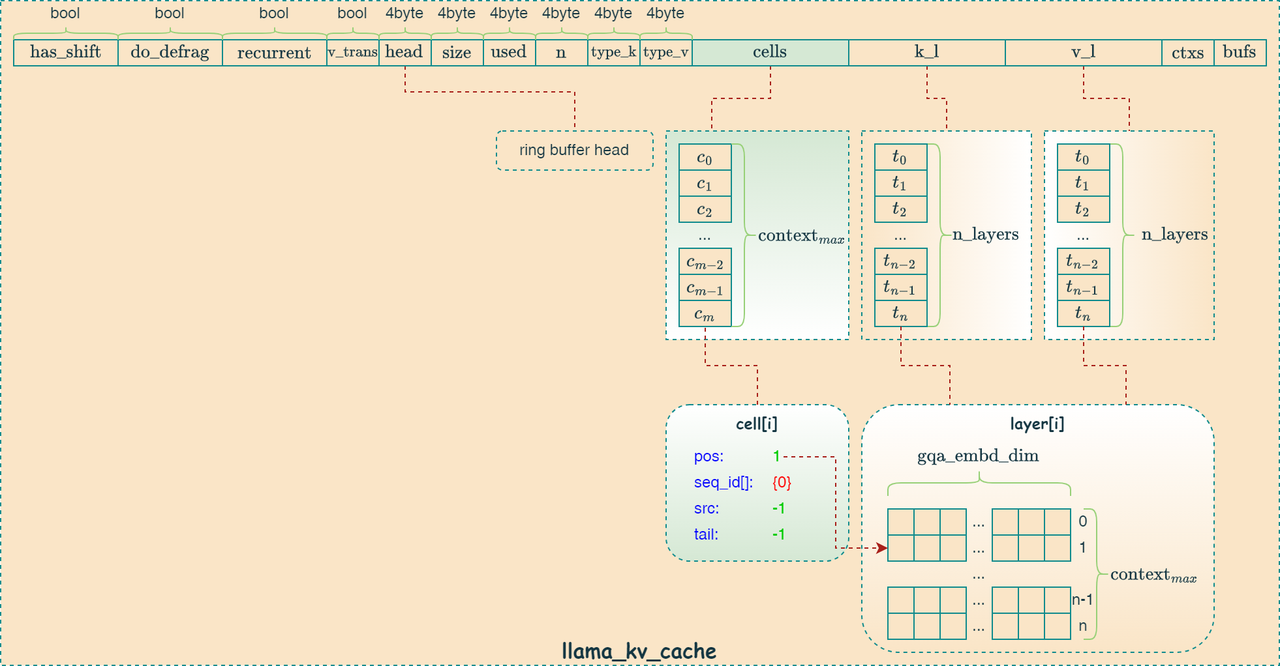
k_l 和 v_l 容器分配
下述代码的核心功能是为每一层 Transformer 模型创建 Key 和 Value 张量,并将它们存储到 llama_kv_cache 结构体中。它根据模型超参数(hparams.n_embd_k_gqa(i) 和 hparams.n_embd_k_s())以及是否启用 GPU OffLoad 来确定张量的维度和存储位置。这段代码确保了 KV 缓存为每一层模型都分配了足够的内存空间来存储 Key 和 Value 数据,为后续的推理计算做好了准备。ggml_format_name 函数用于设置张量的名称,方便调试和可视化。 其中,n_embd_k_gqa 变量的大小为 hparams.n_embd_k_gqa(i) 和 hparams.n_embd_k_s() 两个参数之和。 hparams.n_embd_k_s() 只有 Mamba 和 RWKV 框架才有效。所以 Transformer 框架只有 hparams.n_embd_k_gqa(i) 参数生效,其表达式为 \(n\_head\_embd \times n\_head\_kv\) 。
1 | for (int i = 0; i < (int) n_layer; i++) { |
Allocate Buffer
下述代码的主要功能是为每种类型的后端缓冲区分配内存,并进行初始化。它遍历之前创建的上下文映射 ctx_map ,为每个上下文分配一个后端缓冲区,将缓冲区清零以避免 NaNs,然后将缓冲区句柄存储到 cache.bufs 向量中。这段代码确保了 KV 缓存拥有足够的内存空间,并且内存被正确地初始化,为后续的推理计算做好了准备。
1 | // allocate tensors and initialize the buffers to avoid NaNs in the padding |
KV Cache Update
如下代码是Decode阶段 KV Cache 的更新流程如下:
1 | llama_kv_cache_update(&lctx); |
llama_kv_cache_update
llama_kv_cache_update 负责维护 KV 缓存的有效性和效率,它通过应用K-shift、碎片整理和预留最坏情况下的计算图内存来实现这一目标。
K-shift
RoPE编码的可加性
如下代码验证了RoPE编码的可加性,即张量 r1 和 r2 相等。
1 | const int n_past_0 = 100; |
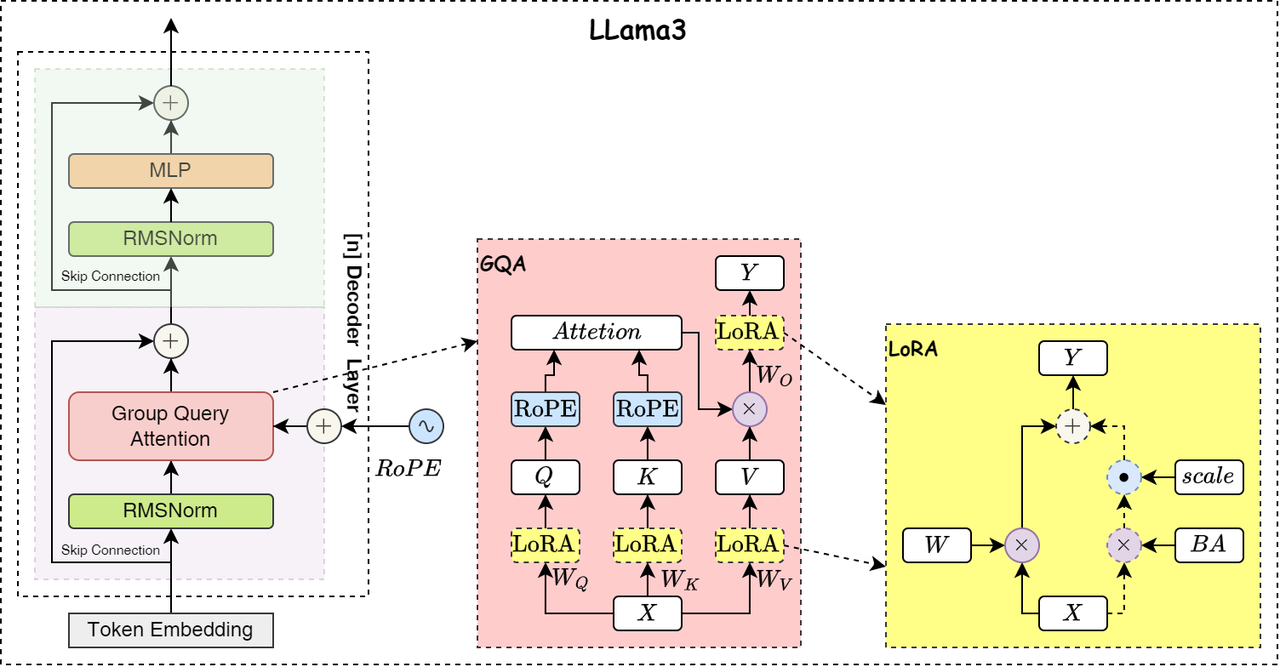
Value 不执行 RoPE
如下图所示,LLM结构中只有 Q 和 K 执行 RopE:
K-Shift 算法
如下代码是 K-Shift 算法的实现,通过构建一个Graph实现对 Cache 中的 Key 向量的 RoPE 修正。
1 | // apply K-shift if needed |
如下图所示,是 K-Shift 算法流程的示意图:
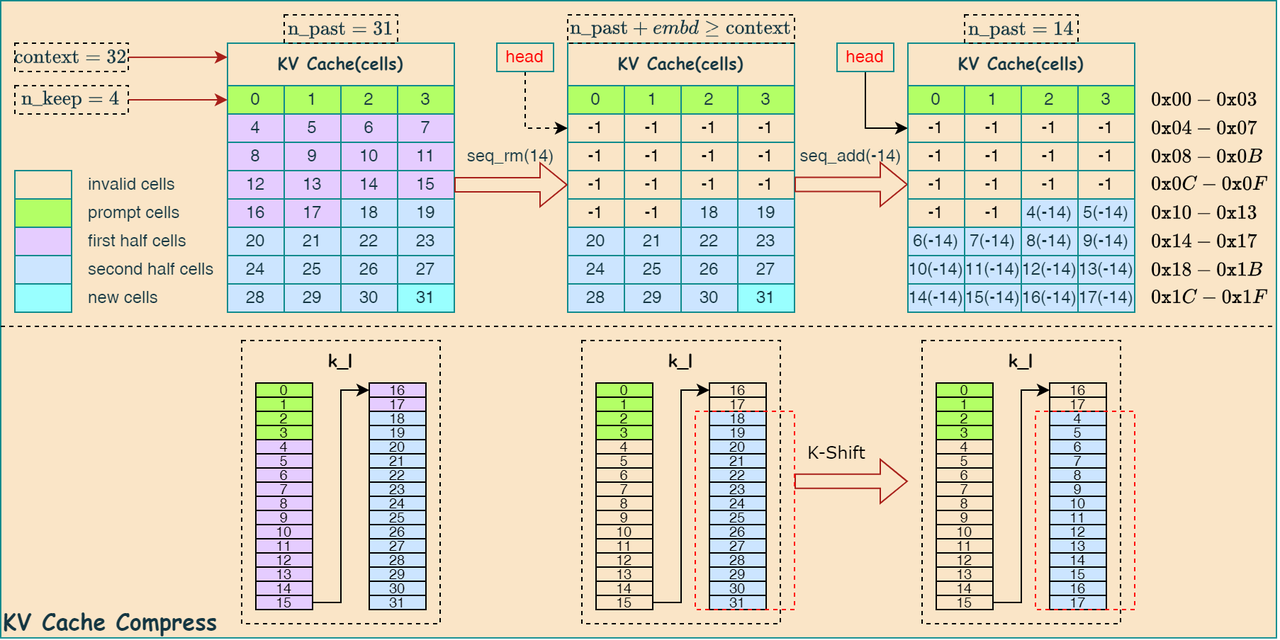
可见,通过对 K 向量添加位置偏移量,实现其位置的修正。
Defragment
关于KV Cache的内存碎片整理代码如下,其主要由 llama_kv_cache_defrag_internal 函数实现,并使能 need_reserve 。
1 | // defragment the KV cache if needed |
llama_kv_cache_defrag_internal 函数主要分为两个功能模块:
更新 ids 映射表
通过更新 ids 映射表, 确定哪些 KV Cache 需要移动到哪里;
找空洞: 从
KV缓存的起始位置开始,寻找连续的空闲单元,使用 \(\text{hole_size}\) 变量表示找到的空洞数量。找数据: 从
KV缓存的末尾开始,寻找连续的有效单元,其数量与找到的空洞数量一致。移动数据: 将末尾的有效单元移动到空洞的位置,并清空原来的单元。
循环执行: 重复以上步骤,直到扫描完整个缓存或达到最大移动次数限制。
构建dedragment图
通过构建 dedragment 图实现KV Cache中的张量数据搬移,这里会用到 cpy 算子, 如下图所示,描述了内存碎片整理的过程,其中,蓝色表示找空洞的过程,红色表示找数据的过程:
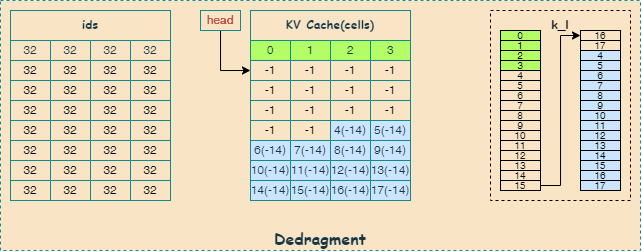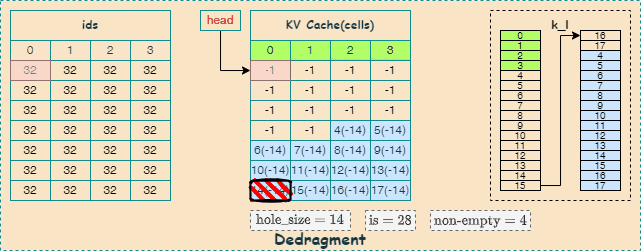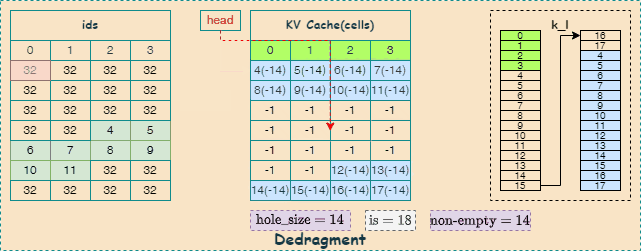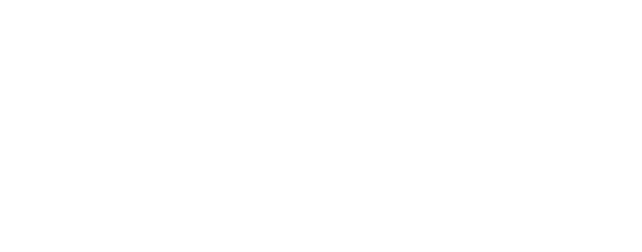
llama_kv_cache_find_slot
llama_kv_cache_find_slot 函数是 KV 缓存管理的核心部分,它负责在缓存中找到合适的空闲 slot,用于存储新的 KV 值。函数根据模型类型的不同采用不同的策略,循环模型注重序列状态的连续性,而非循环模型则更关注找到连续的空闲单元格。
kv_slot_restorer.save(slot)
kv_slot_restorer.save(slot) 函数用于保存当前周期下内存插槽的边界位置信息,当出现异常推理时,便于恢复对缓存的占用。
kv_self.n
1 | if (!kv_self.recurrent) { |
动态调整 kv_self.n 的值来限制参与注意力计算的缓存大小,最小尺寸为pad大小。
1 | static uint32_t llama_kv_cache_get_padding(const struct llama_cparams & cparams) { |
KV Cache Computing And Manage
Prefill and Decode
如下图所示,左图是Prefill阶段的更新的过程,一次性写入所有序列的KV值,右图是Decode阶段的更新过程,每次写入当前序列的KV值,并读取所有的历史KV值:
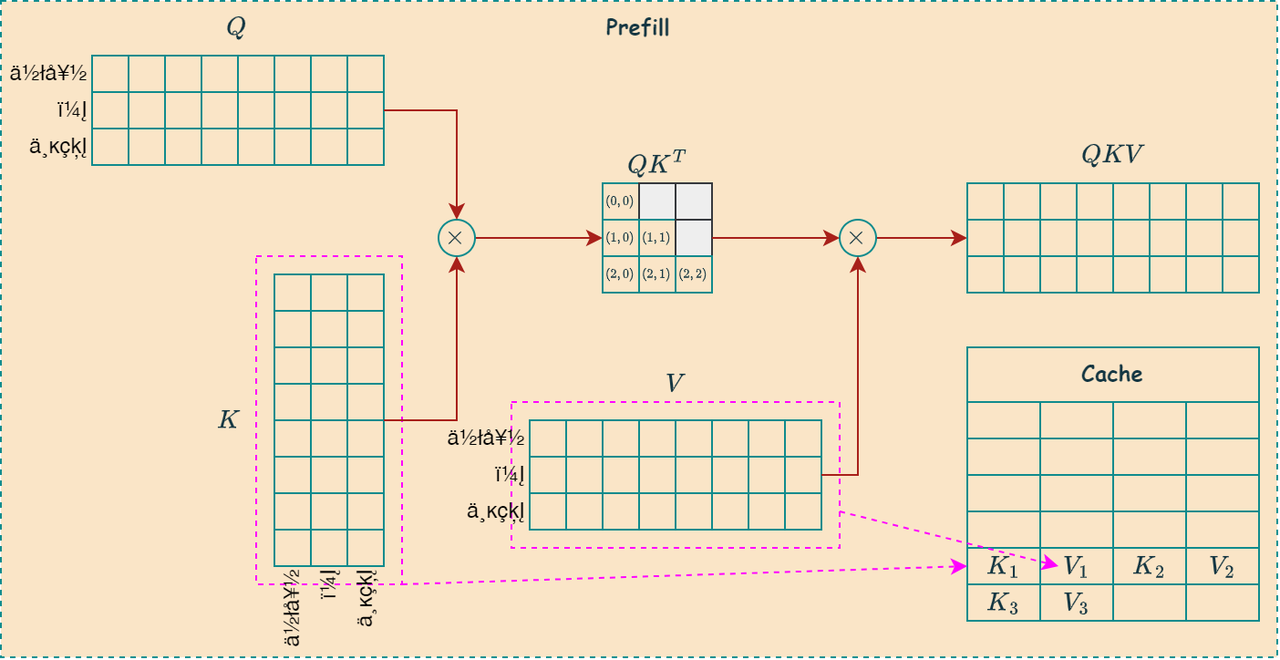
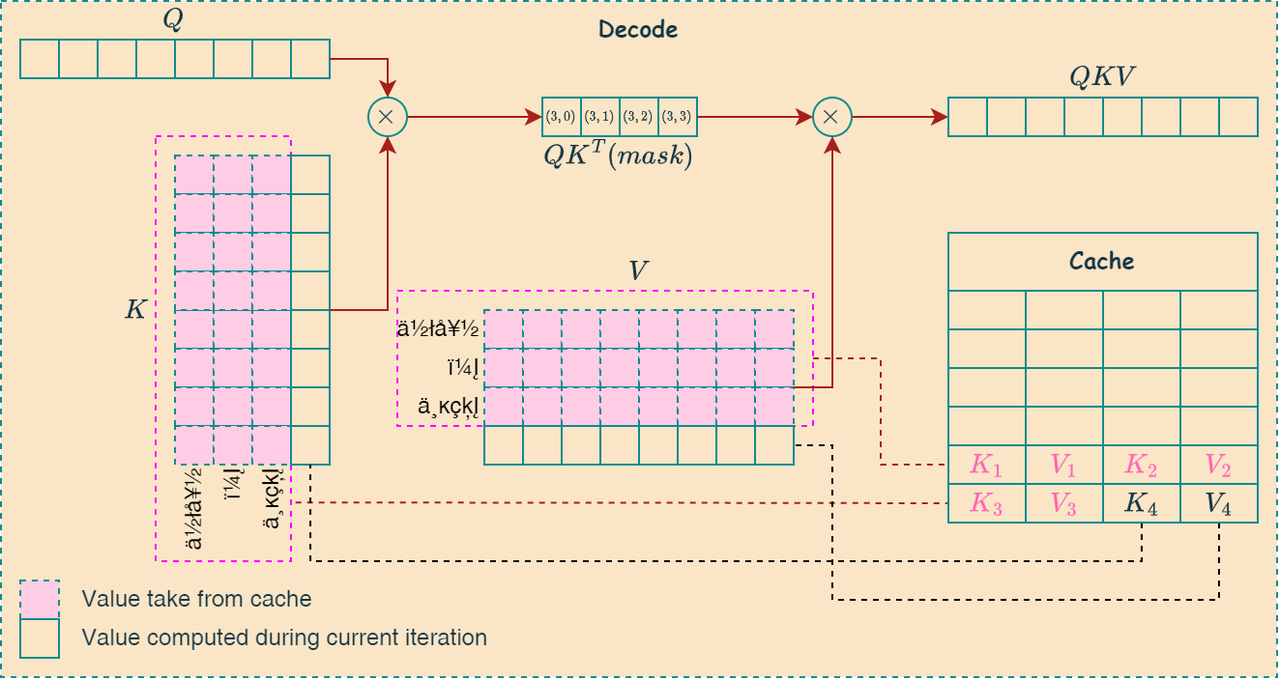
KV Store
llama.cpp中通过调用 llm_build_kv_store 函数,实现对 KV cache 的保存。
1 | llm_build_kv_store(ctx, hparams, cparams, kv, graph, k_cur, v_cur, n_tokens, kv_head, cb, il); |
- K向量
1 | struct ggml_tensor * k_cache_view = ggml_view_1d(ctx, kv.k_l[il], n_tokens*n_embd_k_gqa, ggml_row_size(kv.k_l[il]->type, n_embd_k_gqa)*kv_head); |
- V向量
1 | if (cparams.flash_attn) { |
The Size Of Cache
对于每个token,需要为每个注意力头和每一层存储两个向量,且向量中的每个元素假设按照 fp16 格式存储,则每个token在内存中按照字节存储的缓存大小可以表示为:
\[2_{kv}\times2_{byte}\times head\_dim \times n\_kv\_heads \times n\_layers\]
其中, \(head\_dim\) 表示每个头的 key 和 value 的向量大小, \(n\_kv\_heads\) 表示KV注意力头的数量, \(n\_layers\)表示模型的层数。
| Model | Cache size/token |
|---|---|
| LLama3.2-1B | 32KB |
| LLama3.2-3B | 84KB |
| LLama3.2-11B-Vision | 5MB |
为了容纳单一推理任务的完整上下文大小,我们必须相应地分配足够的缓存空间。更多的时候,可能会以小批量进行,那么cache大小还需要进一步扩大为:
\[2_{kv}\times2_{byte}\times head\_dim \times n\_kv\_heads \times n\_layers \times \color{red}{max\_context\_lenght \times batch\_size}\]
如果想利用LLama3.2-11B-Vision的128K完整上下文能力,且以4个批次推理,则需要缓存的大小将近 2.5TB 的大小,这远大于存储模型参数所需要的 22GB 大小。
因此,KV缓存的大小限制了两件事:
- 系统能够支持的
最大上下文大小; - 系统每个推理时
批次的最大大小;
How To Reduce Cache Size?
如何减小KV Cache的大小,主要从注意力结构的优化下手,比如减少注意力头的数量、优化Cache的存储方式和筛选有效的KV值等。
Grouped Query Attention
分组查询注意力 (Grouped-Query-Attention GQA)是multi-head attention的一种变体,通过减少注意力头的数量,从而减少了KV Cache的大小,大体思想如下图所示:
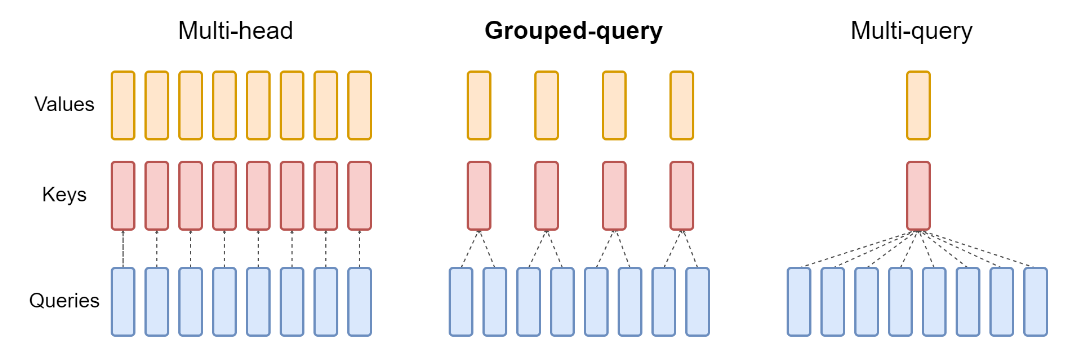
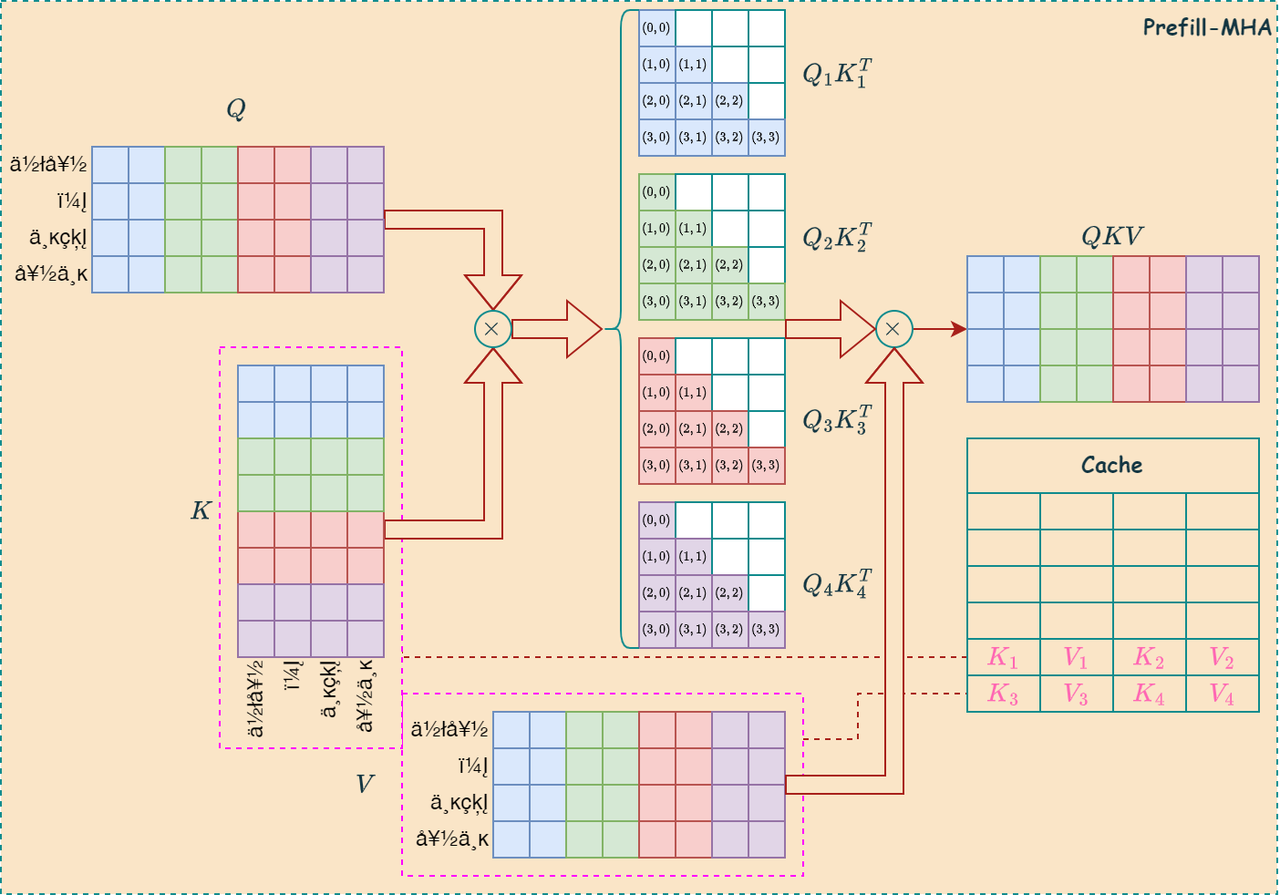
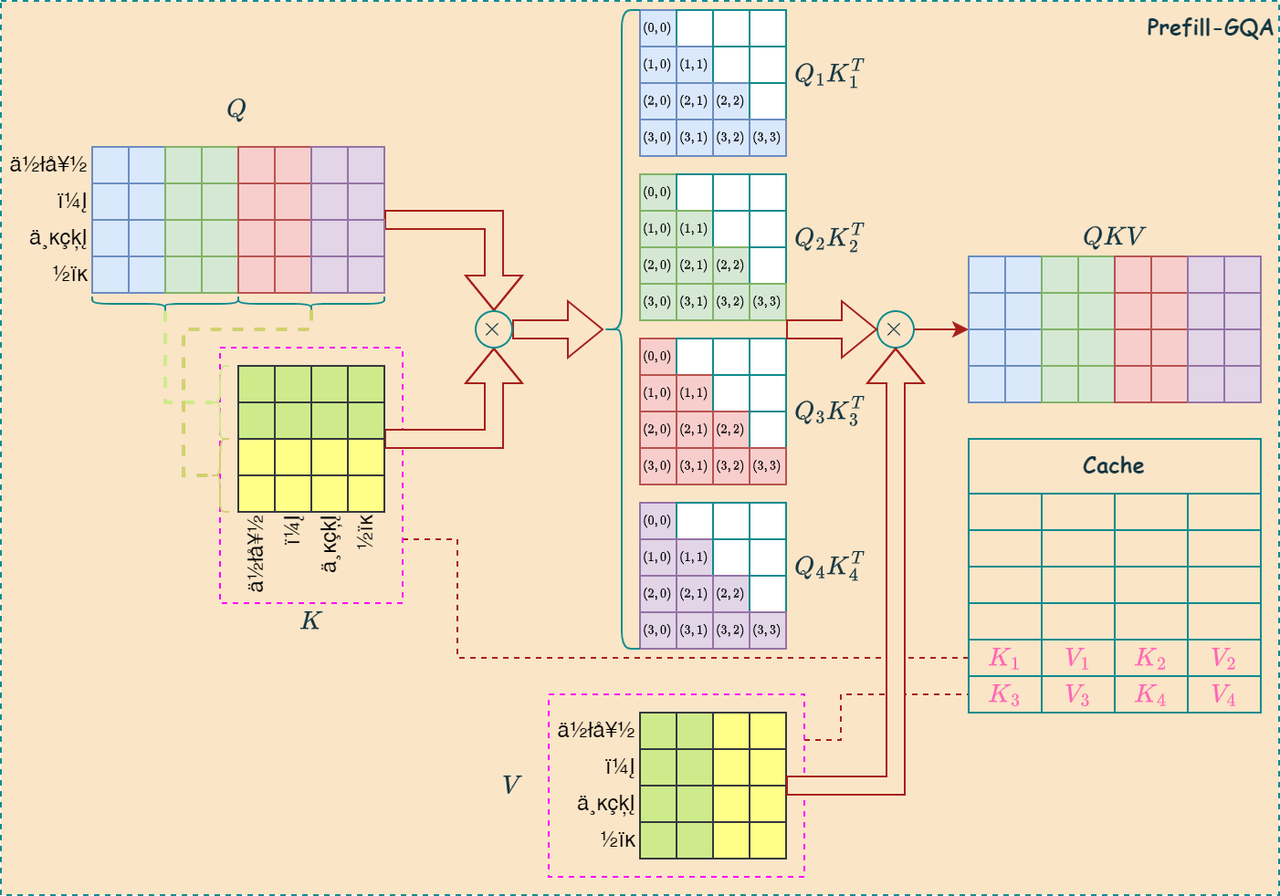
如下左图是MHA的计算过程,右图是GQA的计算过程,可见GQA可以有效减少KV缓存的大小:
Sliding Window Attention
滑动窗口注意力 (SWA) 是 Mistral-7B 用于支持更长上下文长度而无需增加 KV 缓存大小的技术。 SWA是对原始自注意力机制的改进,利用Transformer层的堆叠来关注窗口大小 \(W\) 以外的信息。第 \(k\) 层位置 \(i\) 的隐藏状态 \(h_i\) ,关注于前一层位置在 \(i-W\) 和 \(W\) 之间的全部隐藏状态。递归地,\(h_i\) 可以访问从输入层到距离最远为 \(W\times k\) 个token中的所有token,如下图所示:
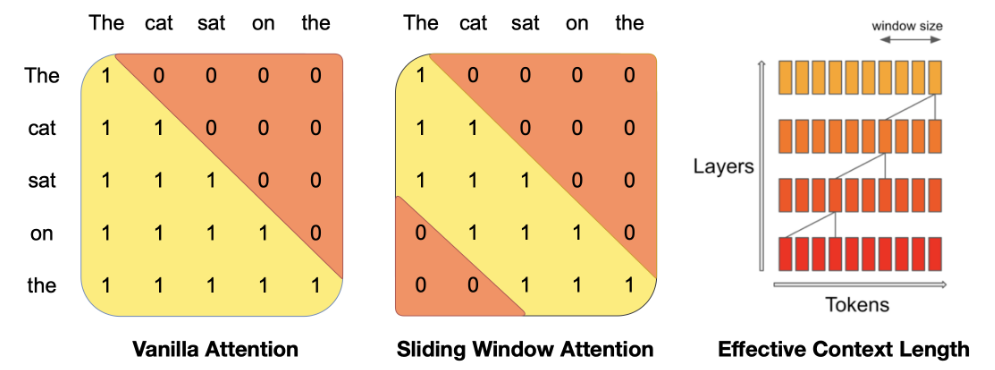
按照下图中的参数,在模型最后一层,使用窗口大小 \(W = 4096\) ,我们具有大约 131K 个 token 的理论注意力跨度。

滚动缓冲区缓存
固定的注意力跨度意味着我们可以使用滚动缓冲区缓存来限制我们的缓存大小。缓存大小固定为 W,时间步 i 的键值对存储在缓存的 \(i \mod W\) 位置。因此,当位置 \(i > W\) 时,缓存中的旧值将被覆盖,缓存的大小停止增长。

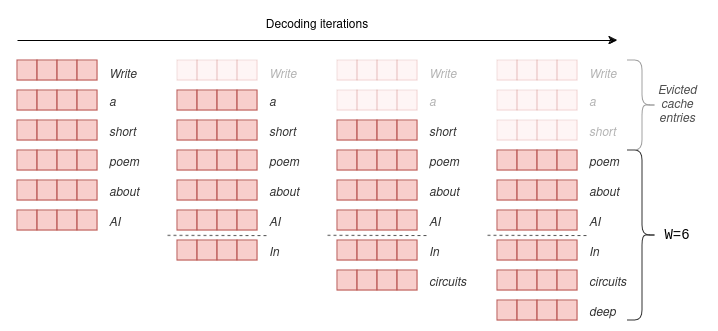
Prefill and Block
生成序列时,我们需要逐个预测标记,因为每个标记都以之前的标记为条件。然而,提示是预先已知的,我们可以用提示预填充 (k, v) 缓存。如果提示词非常大,我们可以将其分割成更小的片段,并用每个片段预填充缓存。为此,我们可以选择窗口大小作为我们的片段大小。因此,对于每个片段,我们需要计算缓存和片段上的注意力。如下图所示,展示了注意力掩码如何在缓存和块上运作。
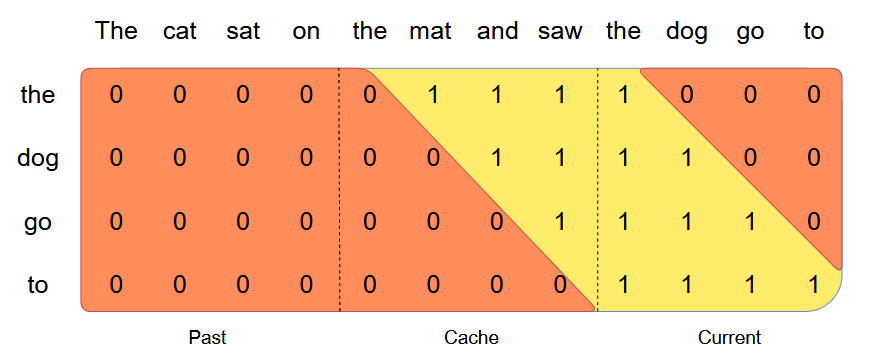
PagedAttention
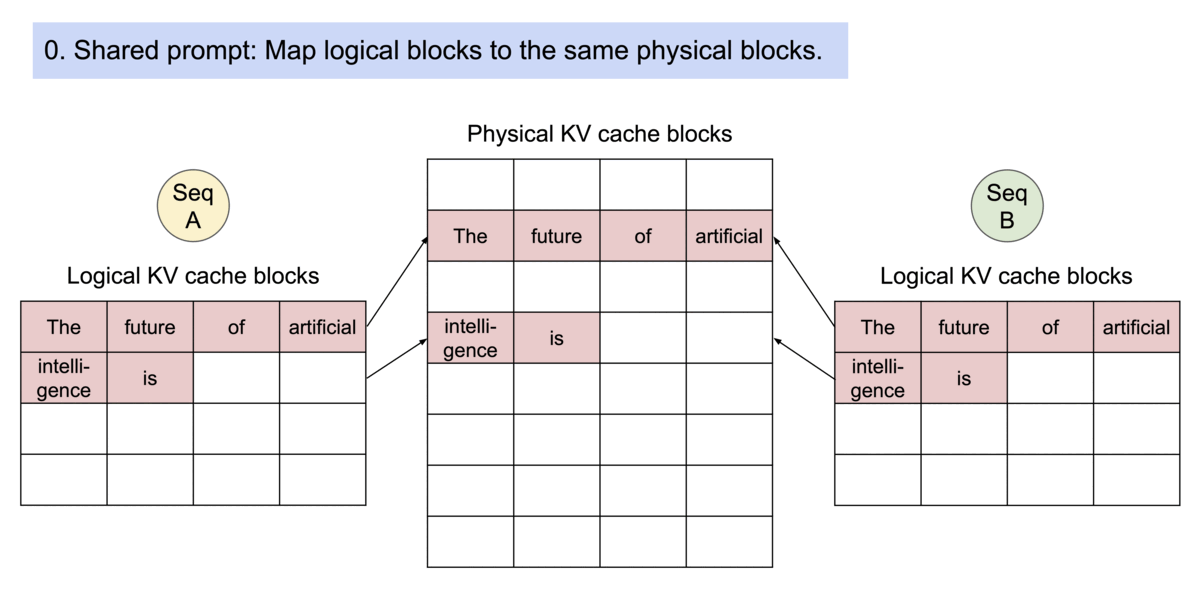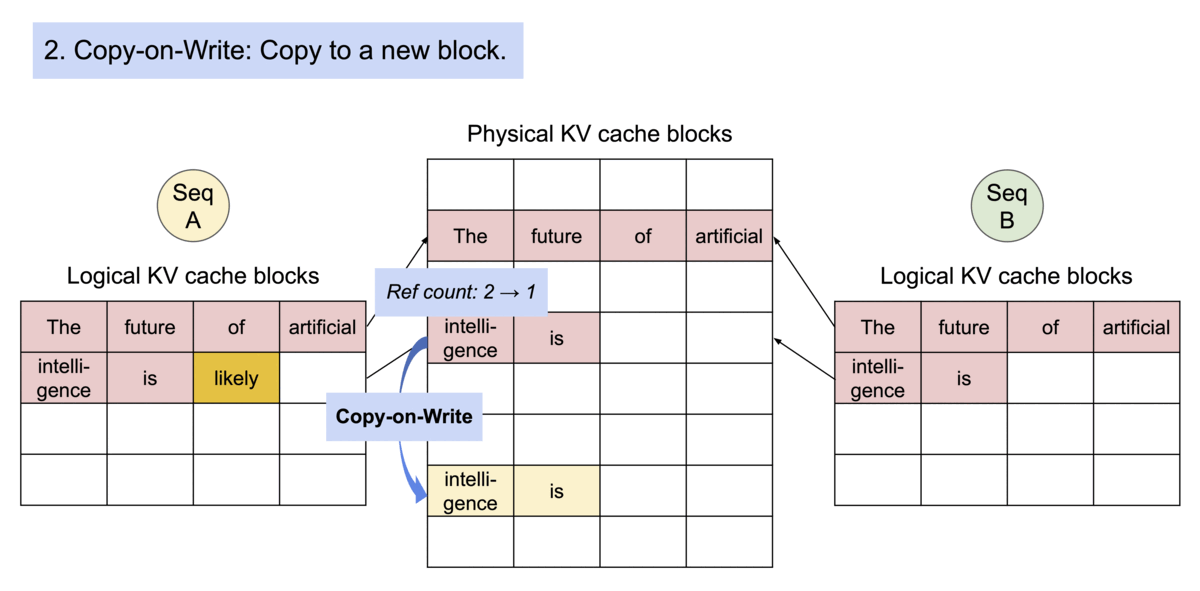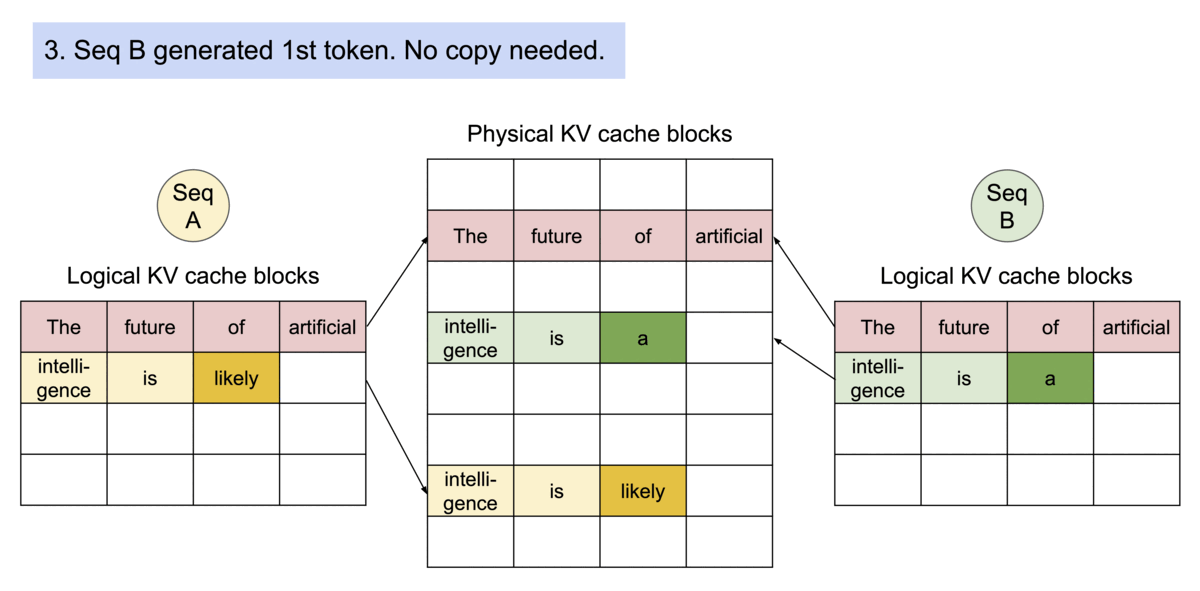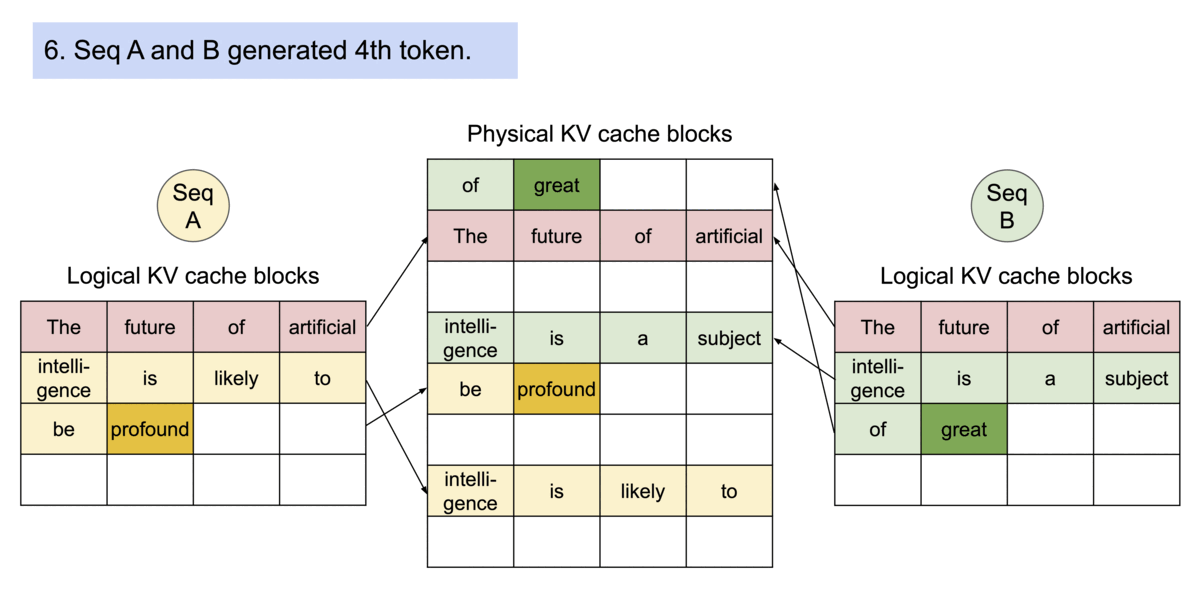
PagedAttention 是一种受操作系统中 虚拟内存 和 分页 经典思想启发的注意力算法,与传统的注意力算法不同,PagedAttention允许将连续的键值对存储在非连续的内存空间中。具体来说,PagedAttention 将每个序列的KV缓存划分为块,每个块包含固定数量标记的键值对。在注意力计算过程中,PagedAttention内核高效地识别并提取这些块。
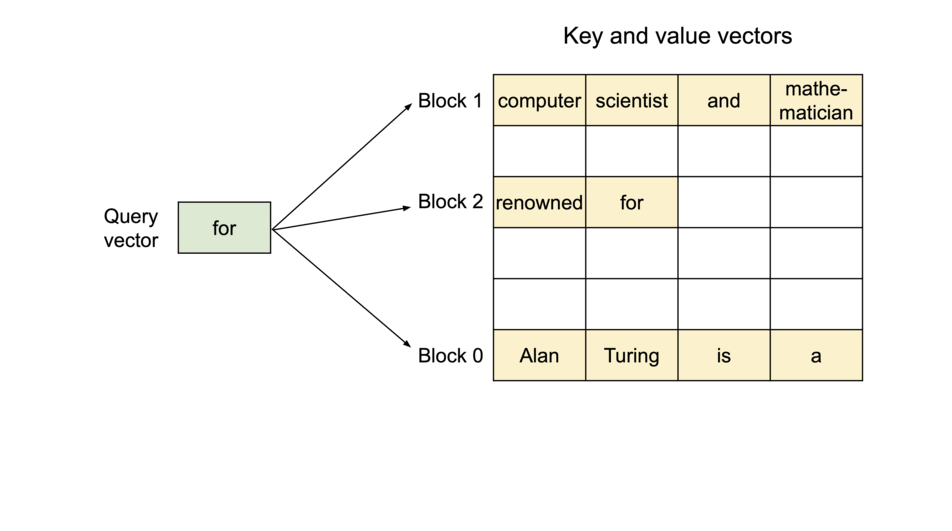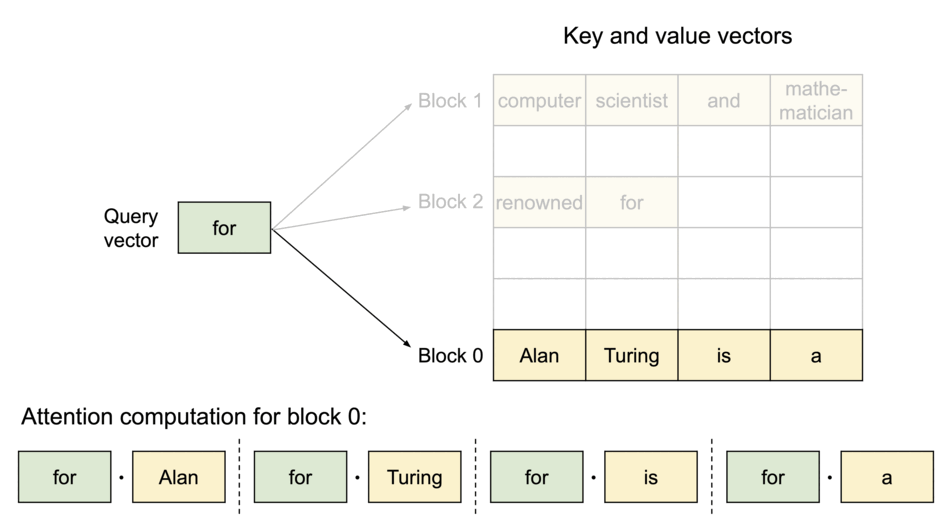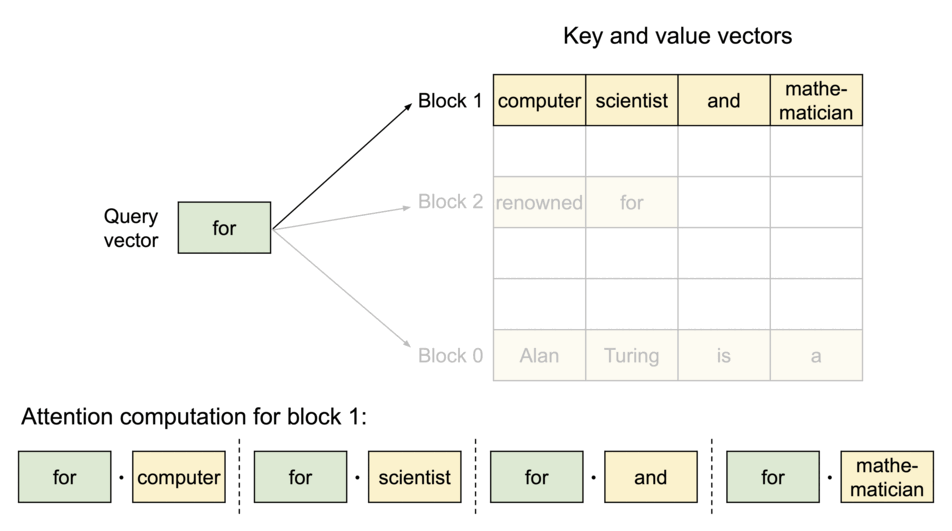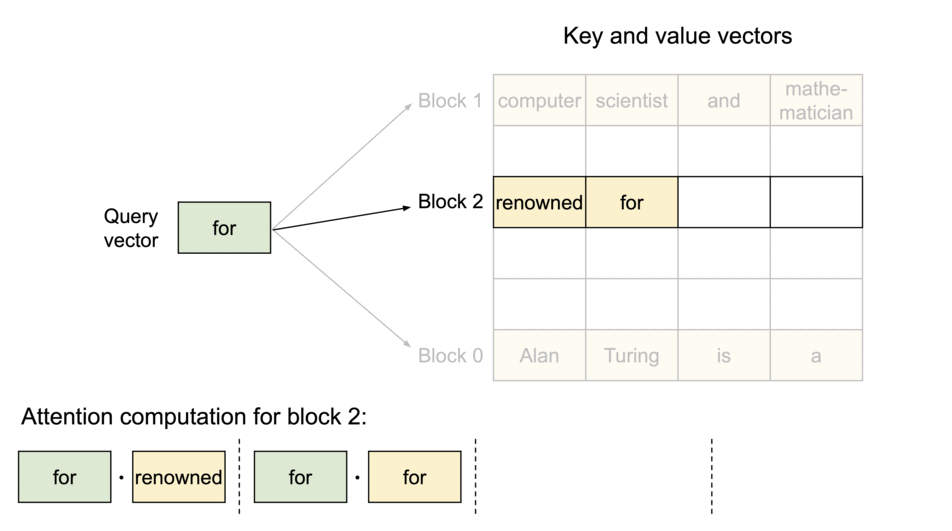
由于块不需要在内存中连续,我们可以像操作系统虚拟内存那样更灵活地管理键值对:可以将块视为页面,标记视为字节,序列视为进程。序列中连续的逻辑块通过块表映射到非连续的物理块,新的token生成时,物理块按需分配。
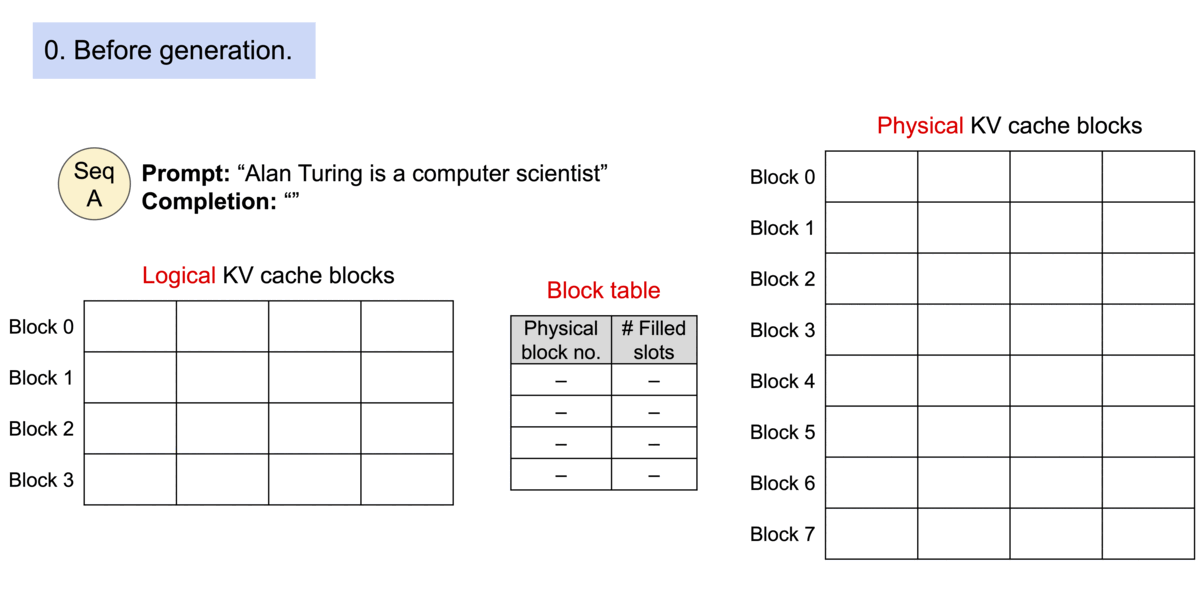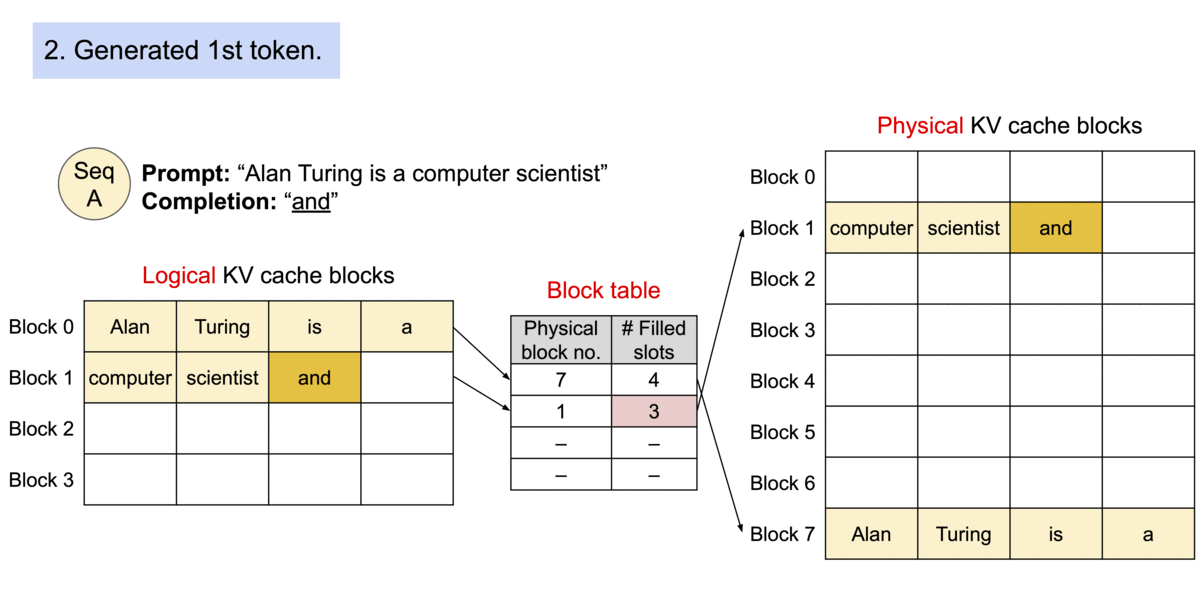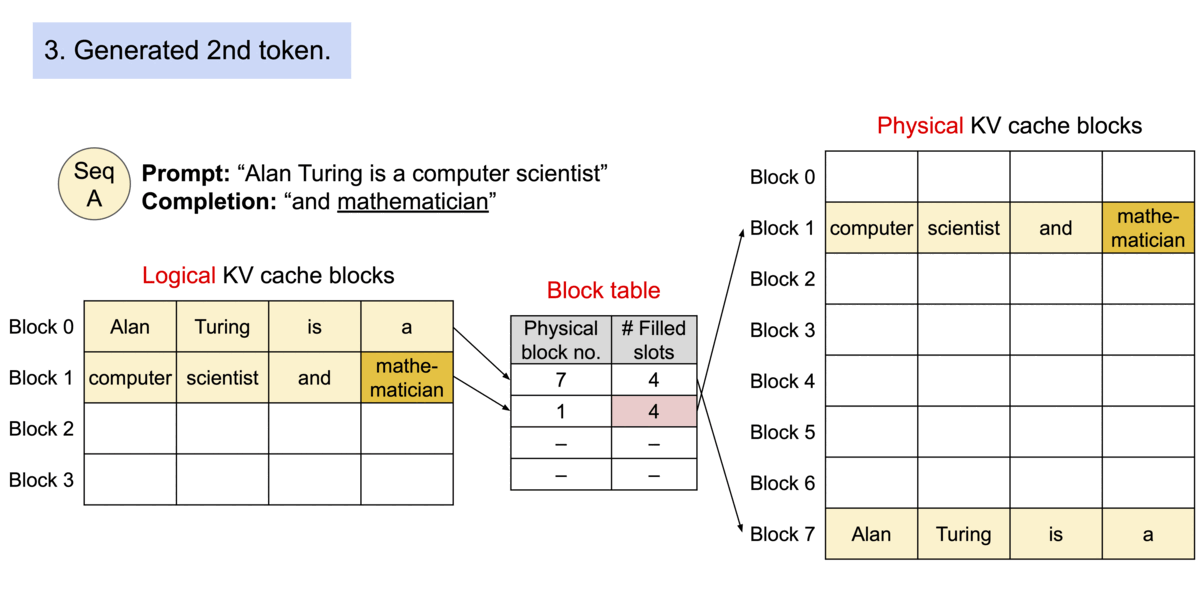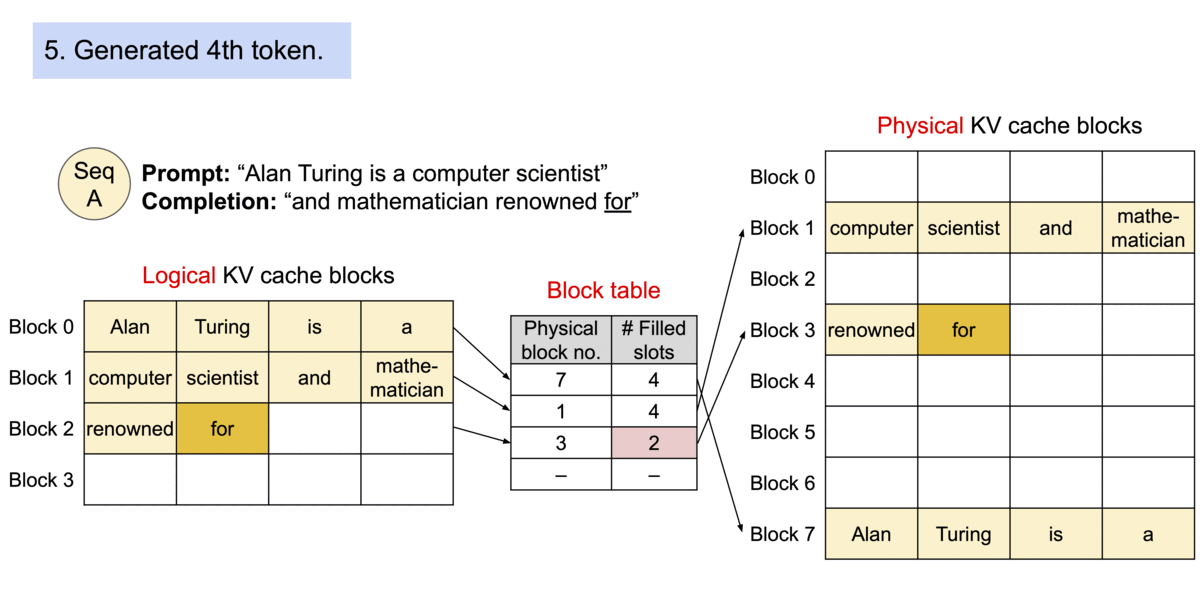
在PagedAttention中,内存浪费仅发生在序列的最后一个块。实际上,这导致了接近最佳的内存使用率,浪费仅低于4%。这种内存效率的提升证明非常有益:它允许系统将更多序列一起批处理,提高GPU利用率,从而显著提高吞吐量。
内存共享
PagedAttention的另一个关键优势在于:高效的内存共享。例如,在并行采样中,多个输出序列是从相同的提示生成的。在这种情况下,提示的计算和内存可以在输出序列之间共享。
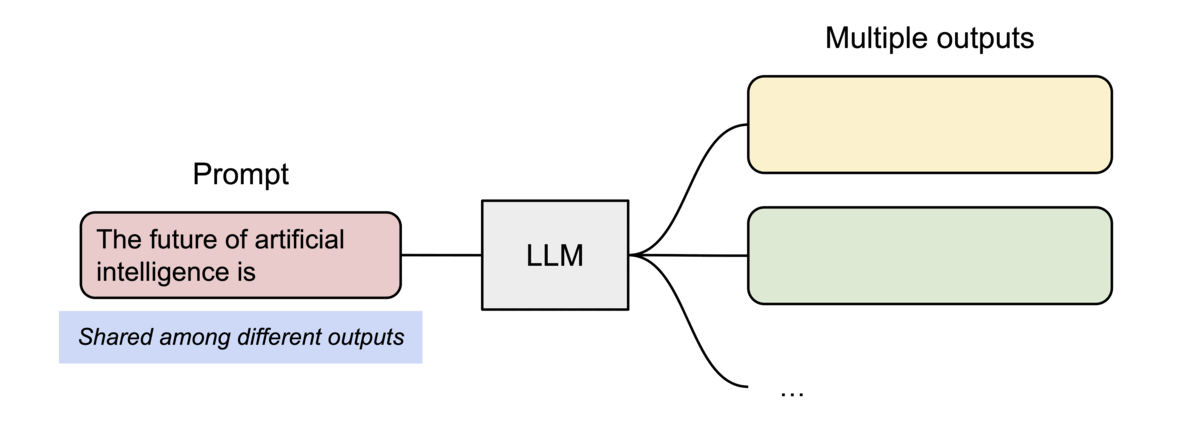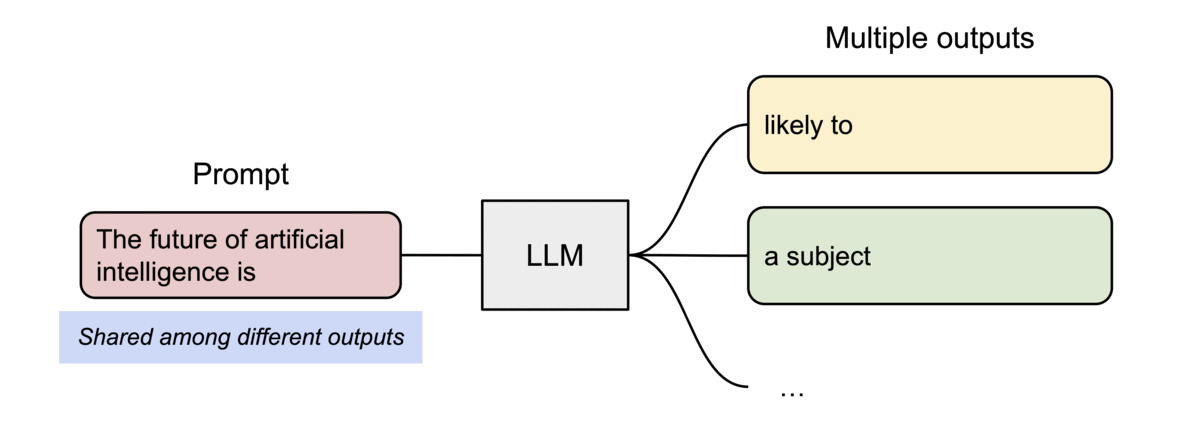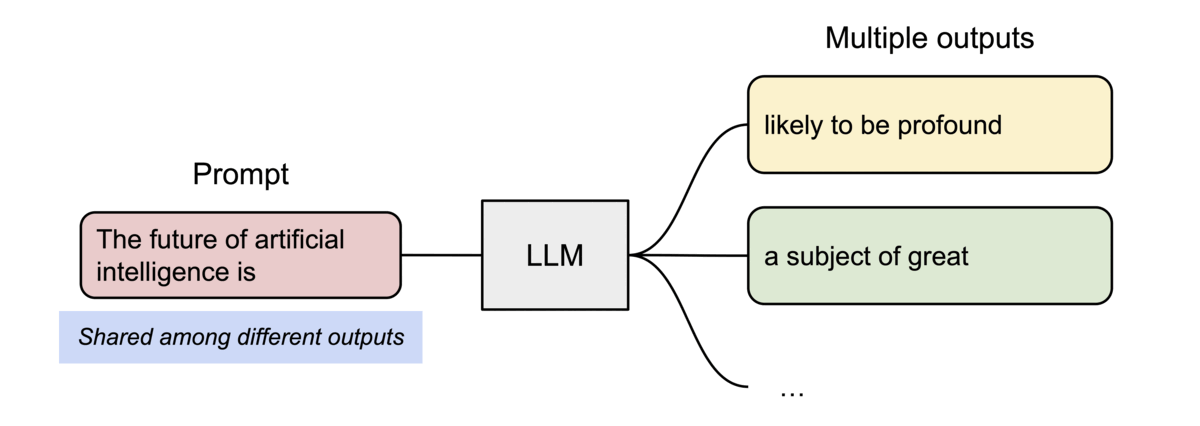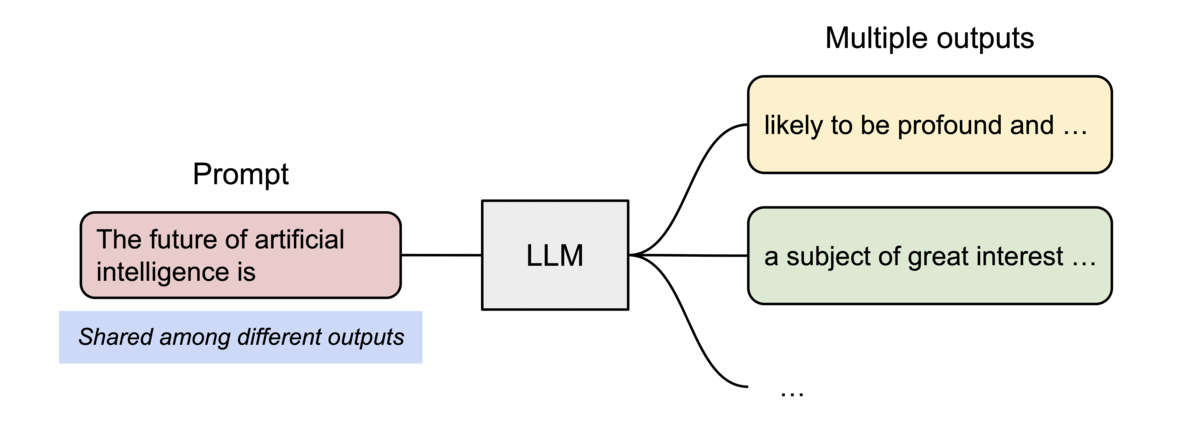
PagedAttention 通过其块表自然地实现了内存共享。类似于进程共享物理页面,不同的序列在PagedAttention中可以通过将其逻辑块映射到相同的物理块来共享这些块。为了确保安全共享,PagedAttention 跟踪物理块的引用计数并实现了写时复制机制。
PageAttention的内存共享极大地降低了复杂采样算法(例如并行采样和束搜索)的内存开销,将其内存使用量减少了高达55%。这可以转化为高达2.2倍的吞吐量提升。这使得此类采样方法在LLM服务中变得实用。
循环缓冲区更新
1 | // update the kv ring buffer |
这段代码实现了 KV 缓存的环形缓冲区更新逻辑。 它将头部指针 kv_self.head 向前移动 n_tokens 个位置,并在超出缓存边界时将其重置为 0。 这使得 KV 缓存可以循环利用存储空间,从而支持处理更长的序列。
缓存碎片管理
llama_kv_cache_defrag_internal 函数通过在 KV 缓存中移动数据来整理碎片,提高缓存利用率。它使用 ggml_graph 来高效地执行数据移动操作。
1 | if (cparams.causal_attn && cparams.defrag_thold >= 0.0f) { |
KV Cache管理-无限文本生成
众所周知,大型语言模型(LLM)难以很好地泛化到长度超过训练序列长度的长文本上下文,这在推理过程中使用LLM处理长输入序列时带来了挑战。在这项工作中,我们认为LLM本身具有无需微调即可处理长文本上下文的能力。为实现这一目标,我们提出SelfExtend方法,通过构建双层注意力信息:组注意力和邻域注意力来扩展LLM的上下文窗口。
SelfExtend
该方法针对基于旋转位置编码(RoPE)的LLM,其内积仅以相对形式的编码位置信息:
\[\langle f_q(x_m,m),f_k(x_n,n) \rangle =g(x_m,x_n,m-n).\]
大型语言模型为何在推理过程中无法处理超过其预训练上下文窗口长度的序列,根据前人的经验,在未见过的相对位置上,其注意力分布与预训练上下文窗口内的注意力分布不同。故这种失败源于分布外 (OOD) 的相对距离,即神经网络对分布外输入不鲁棒。
Grouped Attention
Grouped Attention(GA)与原始的自注意力机制相同,只是在进行内积之前,对每个token的原始位置应用了FLOOR(向下取整)操作。 我们可以使用FLOOR操作将未见位置映射到预训练上下文窗口内的位置。 \[P_g=P // G_s\]
假设LLM预训练的上下文窗口长度为5,而推理序列的长度为8。下图展示了当输入长度超出预训练上下文窗口大小时出现的位置超出分布外的问题。该矩阵的纵轴代表查询词元的位置,横轴代表键词元的位置。在这种情况下,在相对位置矩阵中,只有橙色的部分在预训练期间可见。灰色区域中的相对位置位于预训练上下文窗口之外。
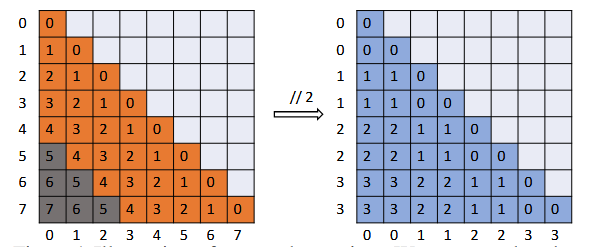
在上述右图中,展示了FLOOR(向下取整)操作的应用方式以及分组自注意力机制的相对位置矩阵。当 \(G_s=2\) 时,查询token和键token的位置由FLOOR (//)从0-7映射到0-3。新的相对位置(蓝色显示)均在预训练上下文窗口的范围内。
分组注意力对模型影响
大型语言模型在没有精确位置信息时似乎能有效工作,但并非十全十美。 如下图所示,虚线表示未进行 FLOOR 运算的原始模型的PPL,实线表示利用 FLOOR 操作的模型PPL。可见,采用分组注意力的大型语言模型在长度超出预训练上下文窗口的序列上能保持相对较低且稳定的困惑度。同时,采用分组注意力机制的模型 PPL 比原始 LLM 略高。
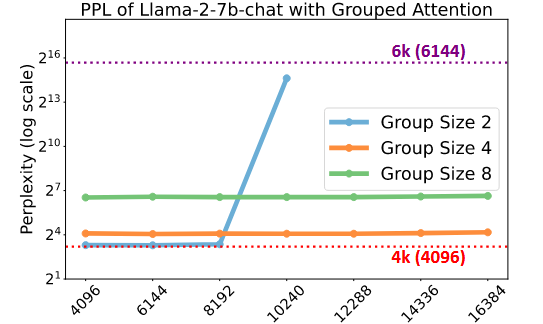
- 如何恢复由分组注意力引起的退化的语言建模能力?
核心思路是在邻近区域重新引入普通注意力,根据一系列的研究表明,与目标token邻近的token,在生成下一个token时,起着至关重要的作用。组注意力可能不显著影响句子整体质量,但需精确定位注意力。保留标准注意力机制,可以确保语言模型捕捉局部上下文细微之处的精确性和有效性。
Self-Extend
SelfExtend是一种无需微调即可增强大型语言模型处理长上下文自然能力的方法,融合了两种不同类型的注意力机制:
- Grouped Attention
这是专门为距离较远的标记而设计的,通过对位置进行下取整运算来处理标记之间的长距离关系。
- Standard Attention
它使用传统注意力机制来处理指定范围内的相邻词元。
注意:SelfExtend仅在推理过程中修改注意力机制,无需额外微调。
如下图所示,上下文窗口从预训练长度7扩展到(7−4)∗2+4=10。
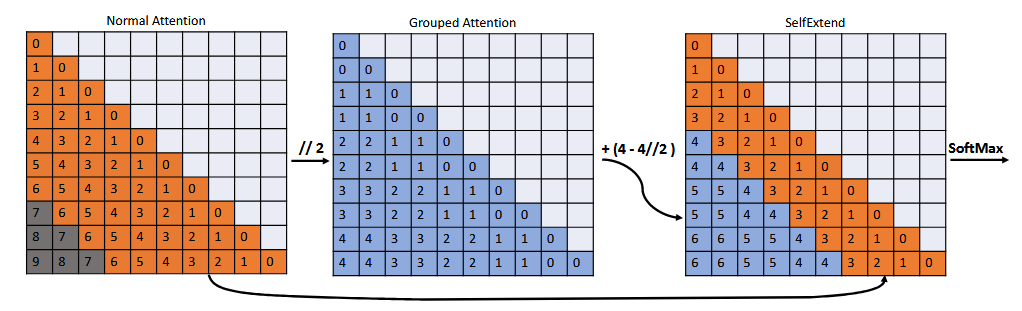
如下图所示,左图是代码实现介绍,右图是对该代码的图形化解释。

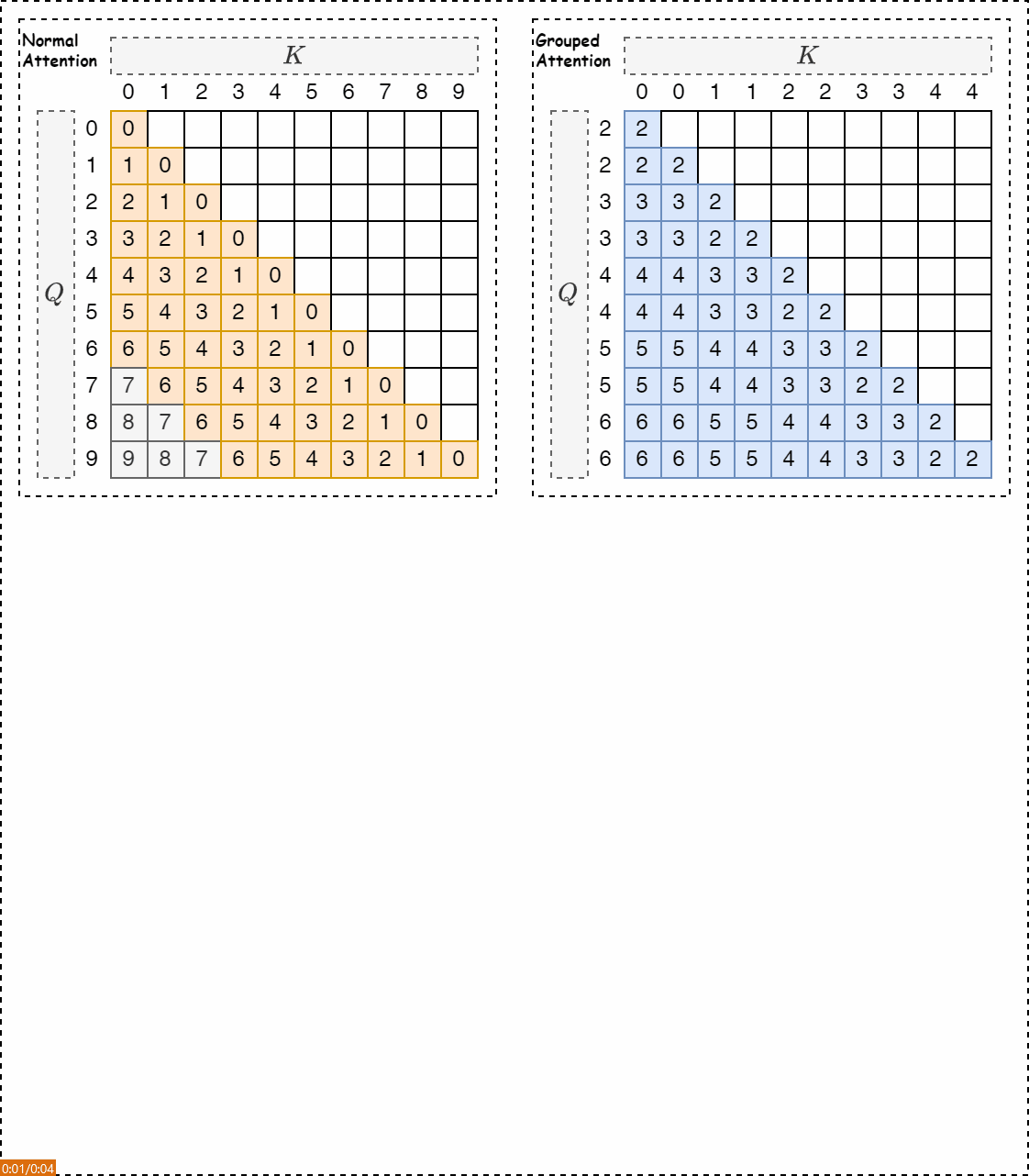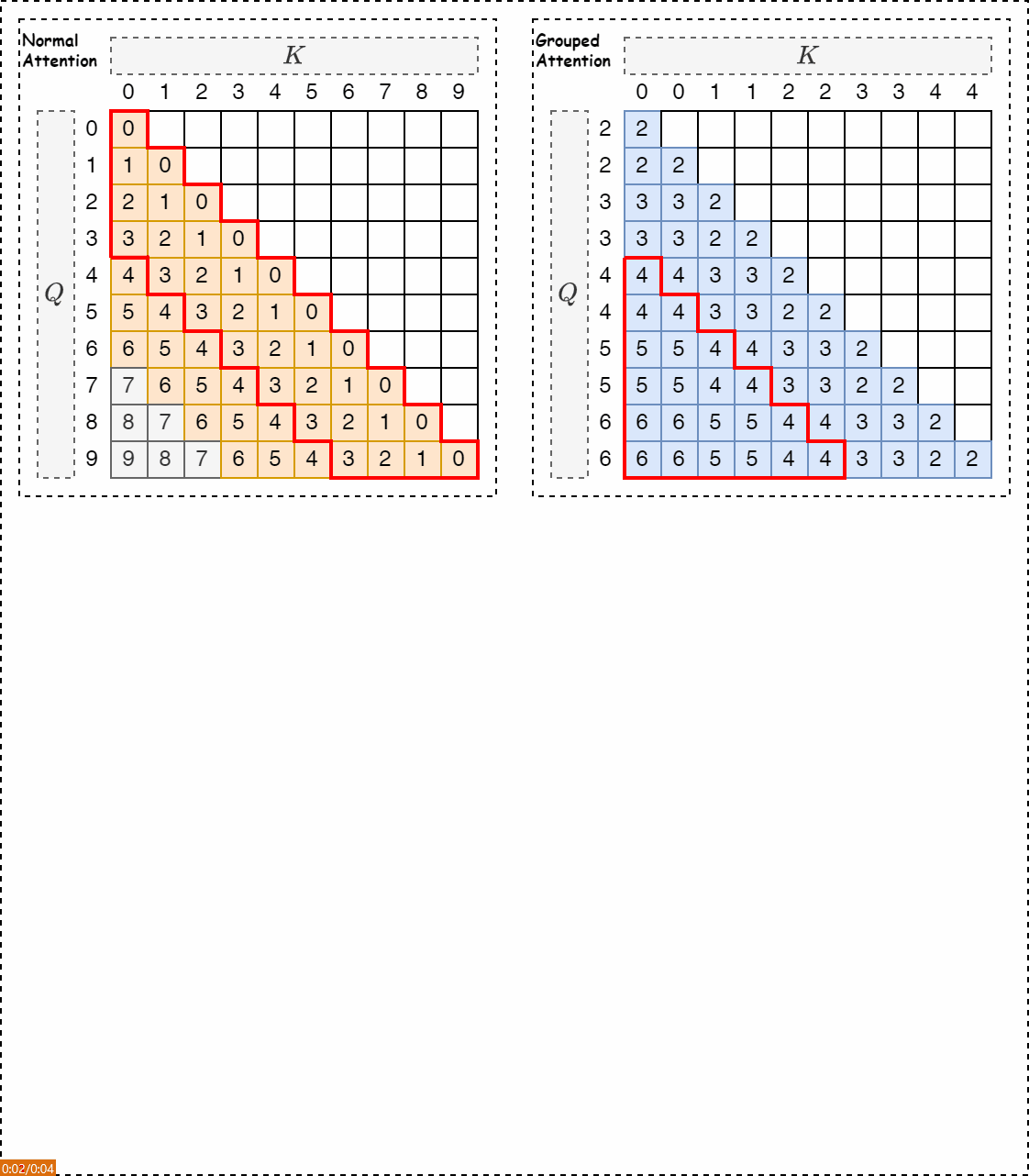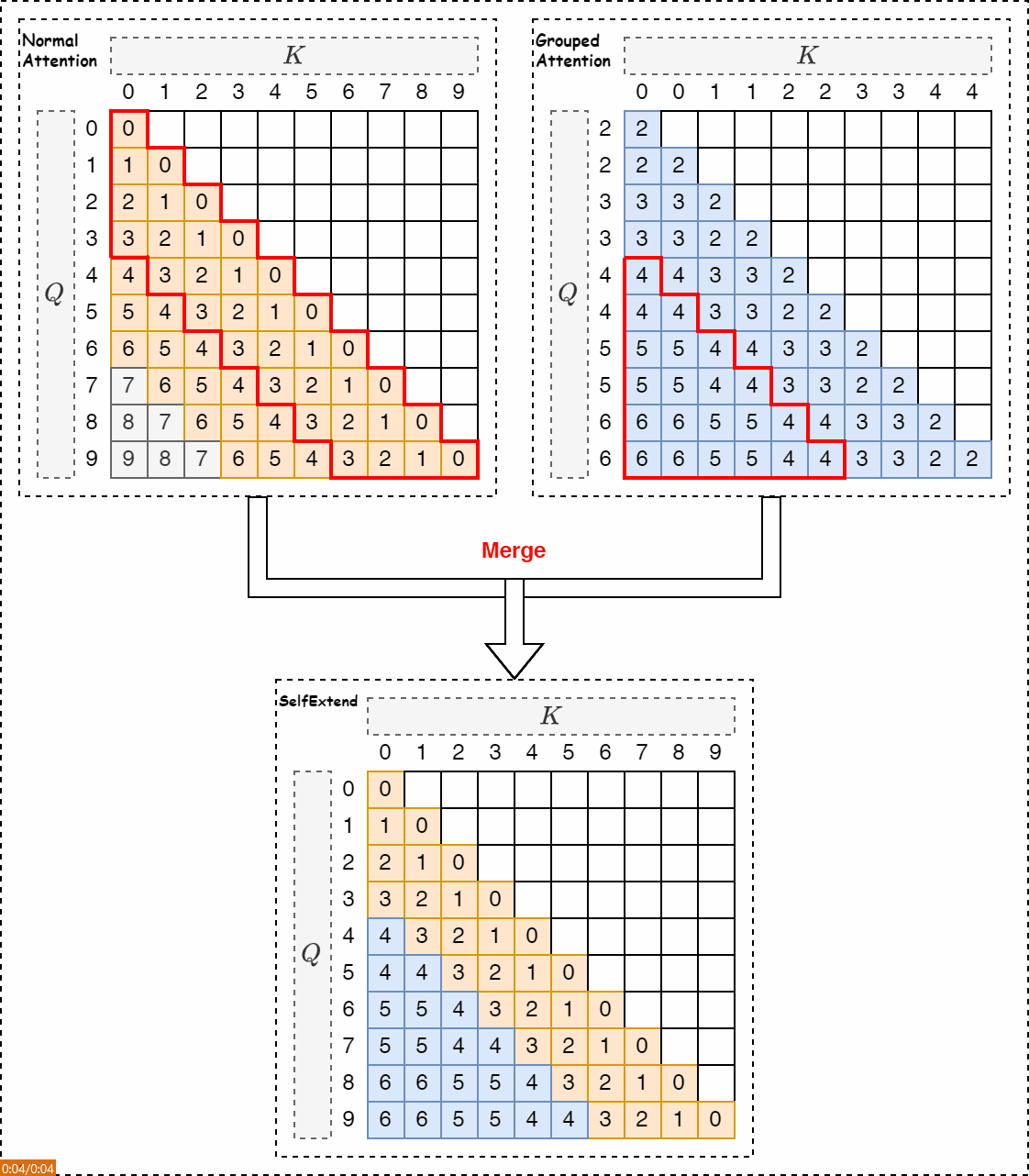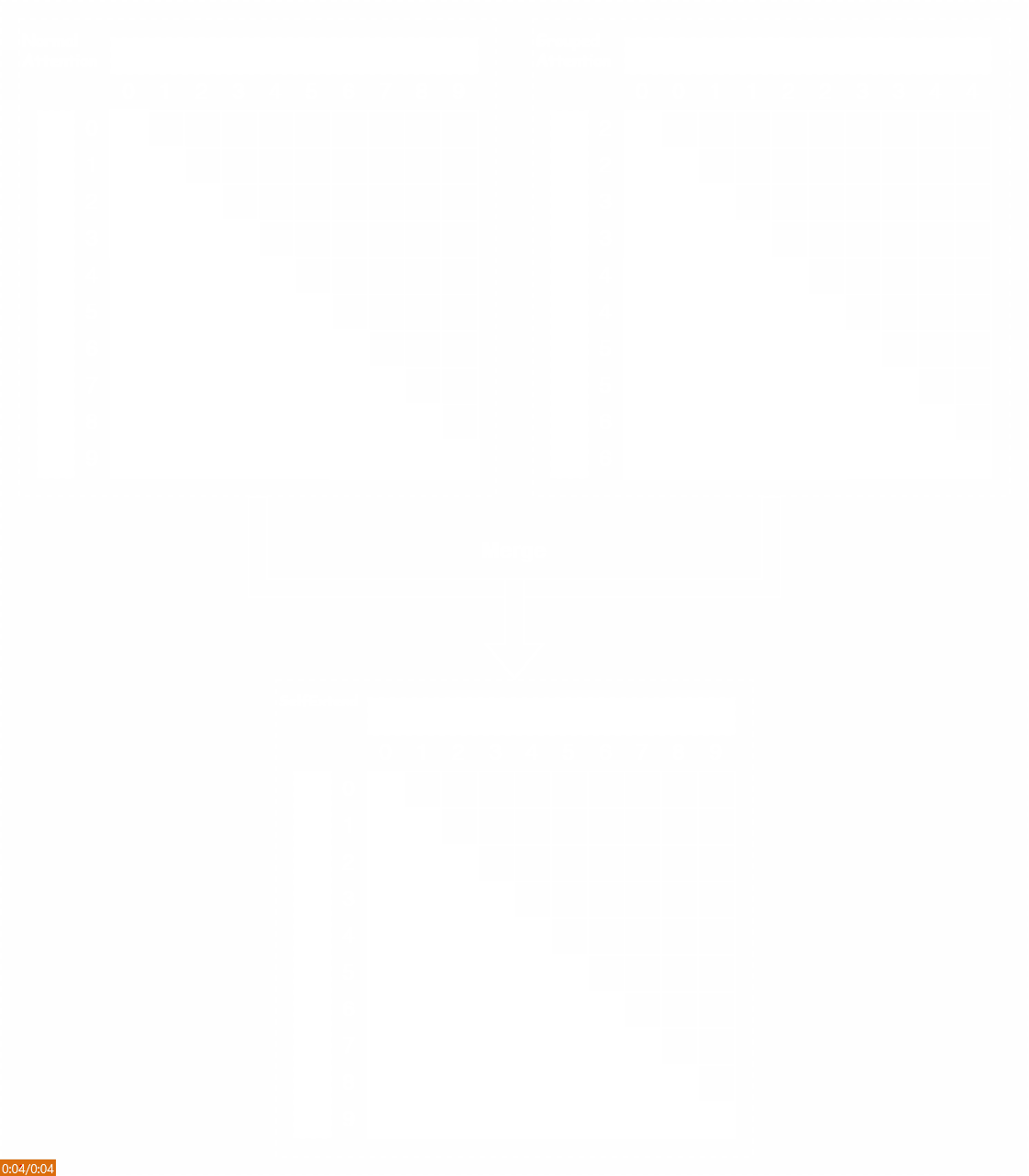
KV Cache管理方案分析
目前llama.cpp中关于无限文本生成的KV Cache管理始终保持Cache大小不变,根据是否采用分组注意力机制,采用不同的Cache更新方式。
- KV Cache更新
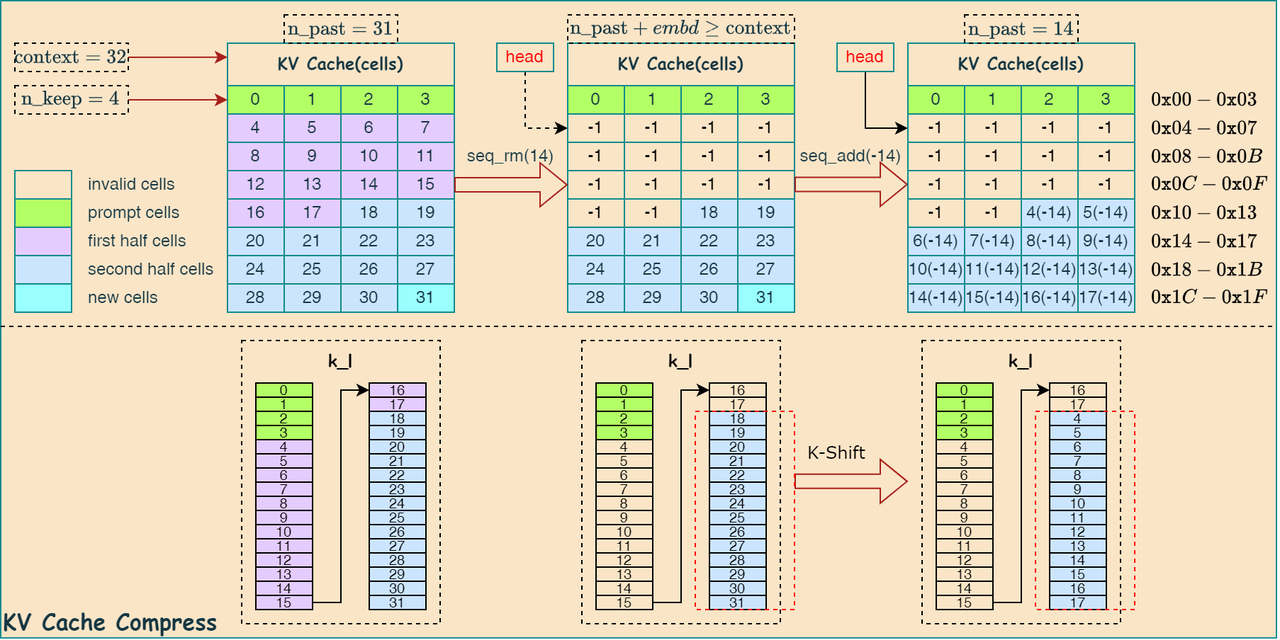
当 ga_n==1 时,会始终保留系统提示词的 KV Cache,从剩余的缓存中移除一半相对当前token较远的token,只保留一半相对较近的token。具体操作的代码实现如下:
1 | if (n_past + (int) embd.size() >= n_ctx) { |
下图描述了上述代码的中的KV Cache更新过程:
- Grouped Attention
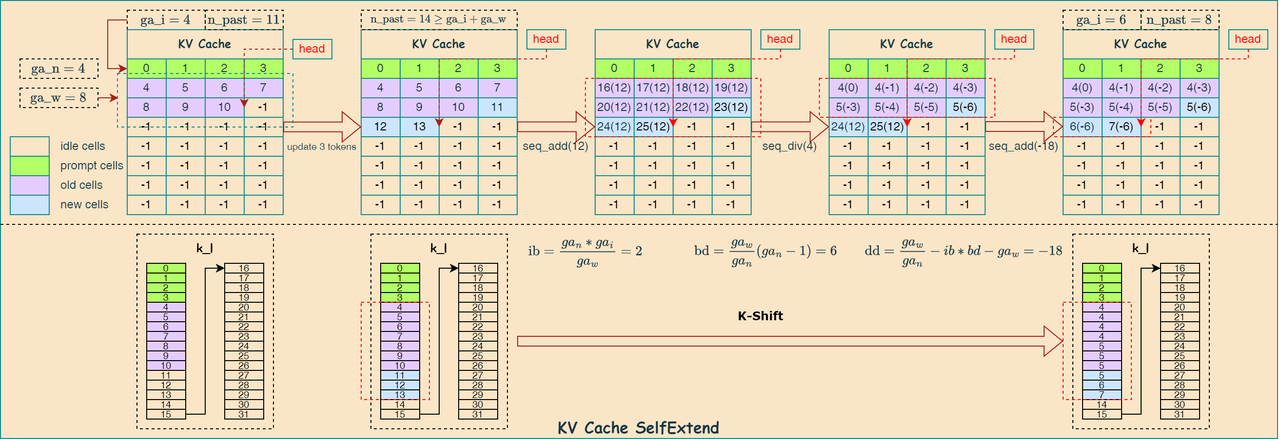
当 ga_n!=1 时,说明采用 grouped self-attention,采用上文提到的 SelfExtend 方法,通过压缩token的相对位置,达到扩展模型上下文的能力,代码实现逻辑如下:
1 | // context extension via Self-Extend |
下图描述了上述代码的实现流程:
Session Load and Save
llama.cpp支持加载历史会话文件,该文件保存了上次会话时位于KV Cache中的数据,如果匹配到提示词在历史会话中,则在decode阶段可以直接加载其KV Cache, 不需要重新计算token的嵌入,可以提升总体性能。
Session file load
首先调用 llama_state_load_file 函数,然后调用 llama_state_load_file_internal 函数,其代码如下:
- 文件校验
1 | // sanity checks |
- 加载保存的token计数
从文件中读取token的数量,代码如下:
1 | // load the prompt |
- 更新上下文的状态
1 | // restore the context state |
其调用 llama_state_set_data_internal 函数更新上下文的状态:
1 | llama_synchronize(ctx); |
其中,KV Cache 使用函数 read_kv_cache 读取更新:
1 | void read_kv_cache(struct llama_context * ctx, llama_seq_id seq_id = -1) { |
其中 read_kv_cache_meta 函数读取 cells 信息, read_kv_cache_data 函数读取每层的 KV cache 数据。