LoRA-llama.cpp
概述
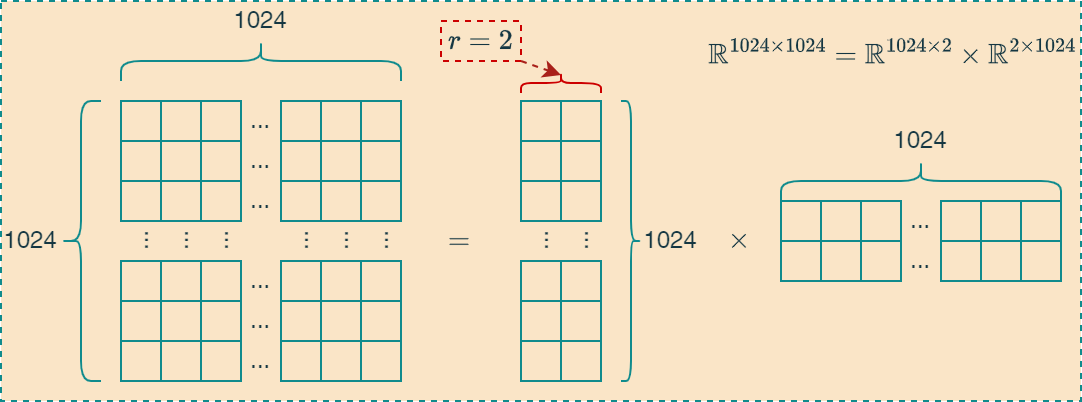
LoRA(Low-Rank Adaption)是微软研究人员2021年提出的一种高效的微调技术,其核心思想就是将大的矩阵分解为两个低秩矩阵表示,从而减少了权重的数据量。如下图所示,将矩阵 \(\Bbb{R}^{1024\times 1024}\)表示为两个低秩矩阵 \(\Bbb{R}^{1024\times 2}\)和 \(\Bbb{R}^{2\times 1024}\)相乘,其中秩的大小为2,可以减少256倍的数据体积。
LoRA
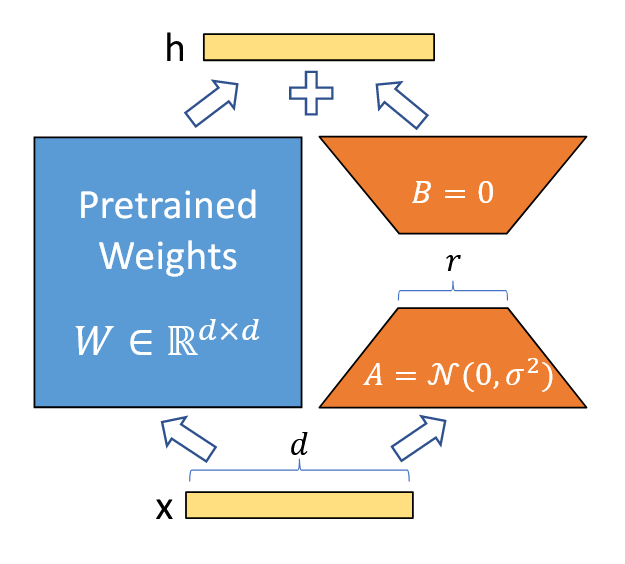
如下图所示,使用高斯随机初始化矩阵 \(A\) ,并将矩阵 \(B\) 初始化为零,因此在训练开始时 \(\Delta W=BA\) 为零。其中, \(W_0 \in \Bbb{R}^{d\times k}\),且矩阵\(B\in\Bbb{R}^{d\times r}\)和矩阵\(A\in \Bbb{R}^{r\times k}\)的秩满足 \(r \ll \min(d,k)\)。
\[\large h=W_{0}x+\Delta Wx=W_{0}x + BAx\]
可以使用缩放因子 \(\frac{\alpha}{r}\)对 \(\Delta Wx\)进行缩放:
\[\large h=W_{0}x+\frac{\alpha}{r}\Delta Wx \]
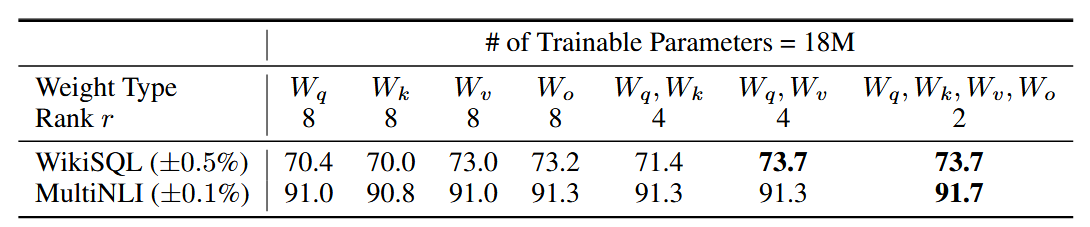
- LoRA 应用于哪些权重矩阵?
需要注意的是,若将所有参数皆纳入\(\Delta W_q\)或\(\Delta W_k\),将会致使精度性能大幅下降,而同时对\(\Delta W_q\)和或\(\Delta W_v\)进行调整,则会产生最优结果。这意味着,即便秩为 4,在 \(\Delta W\) 中亦能够捕捉到充足的信息,故而相较使用秩更大的单一类型的权重,调整多个权重矩阵更为可取。
Loading LoRA
目前llama.cpp中有两种加载lora文件的选项:
--lora
指定LoRA适配器文件的路径;
--lora-scaled
指定LoRA适配器文件的路径和用户定义的缩放系数;
- 可以多次指定
--lora选项可实现加载多个LoRA适配器; - 支持动态加载LoRA文件;
- 支持将LoRA文件参数与基础模型合并;
LoRA Adapter Init
1 | for (auto & la : params.lora_adapters) { |
上述代码其中,llama_lora_adapter_init 函数从lora格式的文件中加载相关信息,判断是否和当前框架匹配,并加载BA矩阵的相关权重参数。
LoRA Format
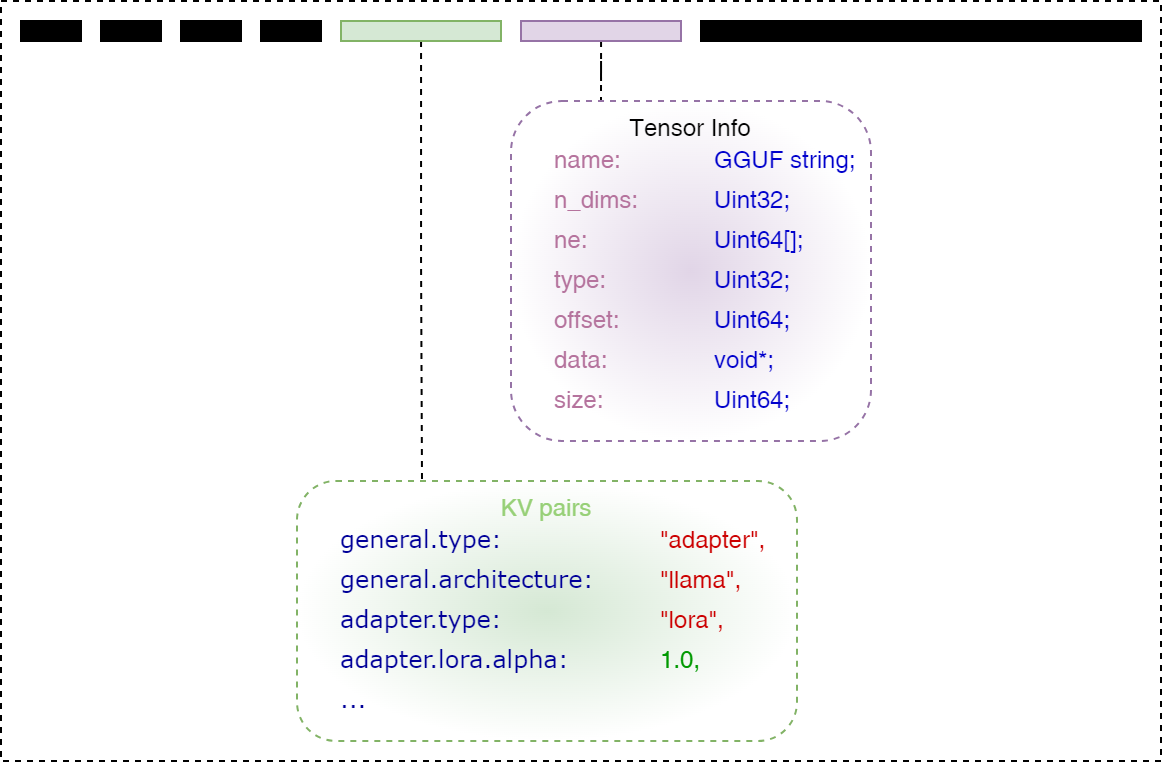
如下图所示,是LoRA文件的结构示意图,主要结构与GGUF格式一致,主要是KV字典中保存与LoRA适配器相关的内容:
llama.cpp中关于LoRA权重的加载实现代码如下:
1 | static struct ggml_tensor * llm_build_lora_mm( |
其中,权重tensor(w)表示匹\(W_Q\),\(W_K\),\(W_V\)和\(W_O\)中的任意一个,如果存在则加载,否则跳过。 关于动态加载的实现,基于判断是否存在 lctx.lora_adapters 对象。如果存在,则在计算图中添加BA矩阵的计算分支,这会增加模型的计算量,但由于BA矩阵的秩比较小,增加的计算量可以接受。