Tokenizer-llama.cpp
概述
如下图所示,是llama.cpp加载GGUF格式模型文件时的调用流程:
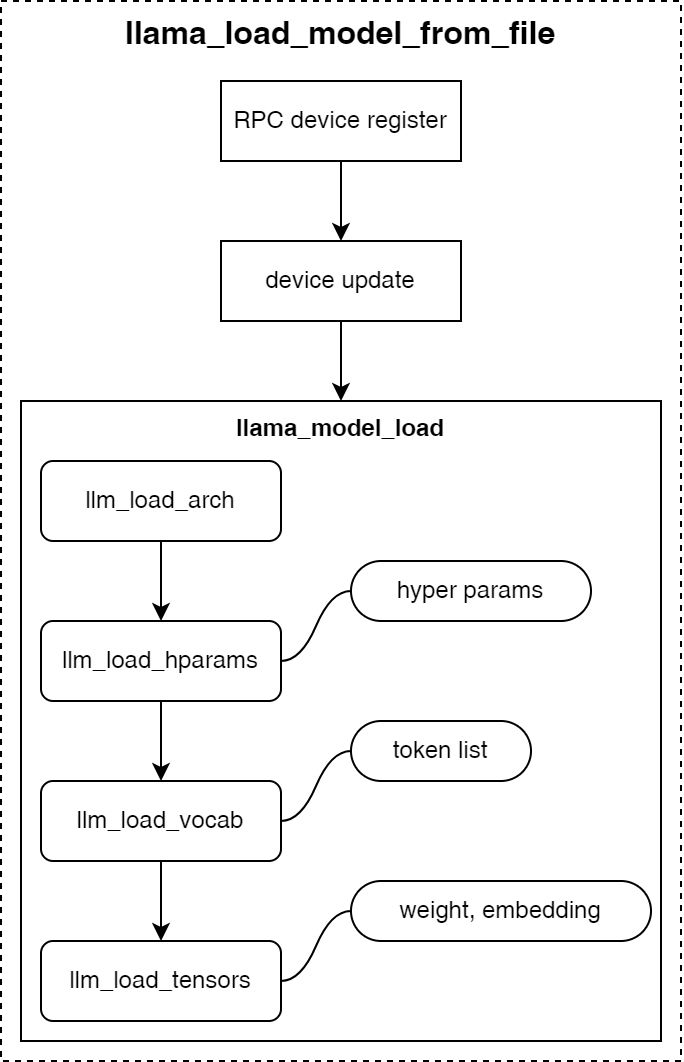
- 首先根据模型配置参数确定模型推理的后端设备类型和模型调用方式;
- 加载获取模型架构类型信息;
- 加载模型的超参数,包括模型名、词表大小、嵌入向量大小、模型层数等模型结构相关的超参数;
Tokenizer
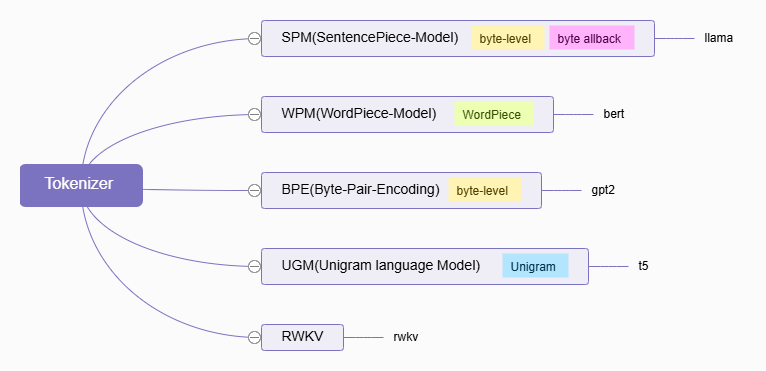
目前llama.cpp实现了5种类型的分词器,分别是:SPM、WPM、BPE、UGM和RWKV,其代码实现位于 llama-vocab.cpp文件中。
Pre-Tokenizer
当分词器类型选择 BPE 时,根据模型的不同,会使用不同的正则匹配项对文本进行预处理。如下下图所示,是目前llama.cpp支持的预分词类型。
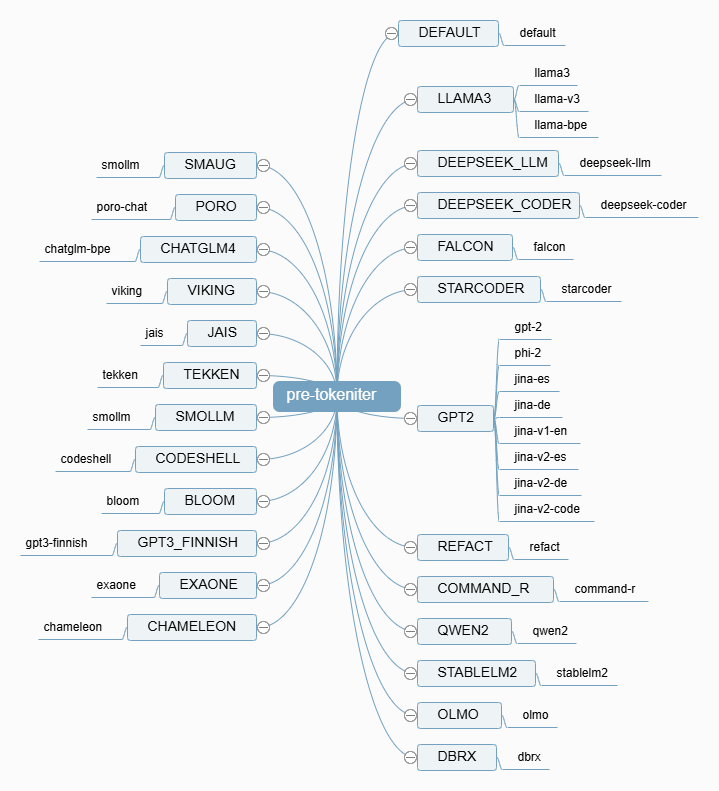
对于一段语句 你好,世界,采用不同的预分词器效果如下:
- LLAMA3
1 | ['你好', ',', '世界'] |
- QWen
1 | ['你好,世界'] |
模型具体的匹配规则一般会存放在tokenizer.json文件的pre_tokenizer字段内。
Collapsed Codepoints
llama.cpp 中文本折叠后再进行匹配是一种权衡性能、兼容性和功能实现的优化策略。它通过将复杂的 Unicode 字符和类别映射到简单的单字节表示,降低了正则表达式引擎的计算负担,提高了匹配效率,并绕过了一些标准库正则引擎的限制,从而更好地支持 Unicode 文本处理。这种优化在处理大型文本和需要频繁进行正则表达式匹配的场景下尤为重要。
判定折叠
如果正则表达式中存在 p{N},p{L}或p{P} 中任意一个匹配项,就会开启折叠功能。
1 | static const std::map<std::string, int> k_ucat_enum = { |
折叠规则
- ASCII 字符保持不变。
- 空格字符(包括 Unicode 空格)被替换成垂直制表符 0x0B。
- Unicode 类别字符被替换成 k_ucat_cpt 中定义的对应字节。
- 其他 Unicode 字符被替换成 0xD0(作为 fallback)。
1 | static const std::map<int, int> k_ucat_cpt = { |
1 | static const std::map<int, std::string> k_ucat_map = { |
设计原则
性能优化
- 降低正则表达式复杂程度:Unicode 类别(例如
\p{N}、\p{L}、\p{P})能够在正则表达式中匹配众多 Unicode 字符。倘若直接采用原始 Unicode 文本以及包含 Unicode 类别的正则表达式予以匹配,会致使正则表达式引擎必须处置大量的字符变体,进而降低匹配效率。借由将 Unicode 类别折合为单字节表示,能够把繁杂的 Unicode 匹配问题转变为简易的单字节匹配问题,大幅提升匹配速度。 - 精简匹配流程:折叠后的文本和正则表达式仅涵盖 ASCII 字符以及少量特殊字节,这让正则表达式引擎的匹配流程更为简便和迅捷。相较于处理复杂的 Unicode 字符集,单字节匹配的计算量要少很多。
兼容性与功能实现
- 绕过标准库正则引擎的限制: C++ 标准库 std::regex 对 Unicode 的支持有限,可能无法完全匹配所有的 Unicode 类别。通过将 Unicode 类别预先处理成单字节表示,可以绕过标准库正则引擎的限制,实现对 Unicode 类别的匹配。
- 统一处理逻辑:折叠后的文本和正则表达式使用统一的单字节编码,简化了代码逻辑,使得代码更容易维护和理解。无论是处理 Unicode 类别还是普通 ASCII 字符,都可以使用相同的匹配逻辑。
Tokenize
下文列举了 llama.cpp 目前支持的分词器类型,并对各个分词器的特性和细节进行了描述,具体类型与模型关系如下:
SPM
SPM(SentencePiece Model)是一种基于字节对级别 BPE(Byte-Pair Encoding)的分词方法,并带有字节回退机制,它在处理多语言文本时具有较好的性能。 SPM 分词器将输入文本分割为字节序列,并通过学习字节对的出现频率来构建词汇表。在分词过程中,SPM 会根据词汇表中的字节对来分割文本。字节回退机制指的是,当遇到不在词汇表中的字节时,SPM 会尝试将其与相邻的字节组合成字节对,以提高分词的准确性。 SPM 分词器在自然语言处理任务中被广泛应用,特别是在处理低资源语言和多语言文本时具有优势。
WPM
WPM(WordPiece Model)是一种基于 WordPiece 的分词方法。它将输入文本分割为单词片段,并通过学习单词片段的出现频率来构建词汇表。在分词过程中,WPM 会根据词汇表中的单词片段来分割文本。 与 SPM 不同的是,WPM 主要关注单词层面的分割,而不是字节层面。它适用于处理以单词为基本单位的语言,如英语等。 WPM 分词器在自然语言处理任务中也有广泛的应用,特别是在处理以单词为主要单位的文本时表现出色。
BPE
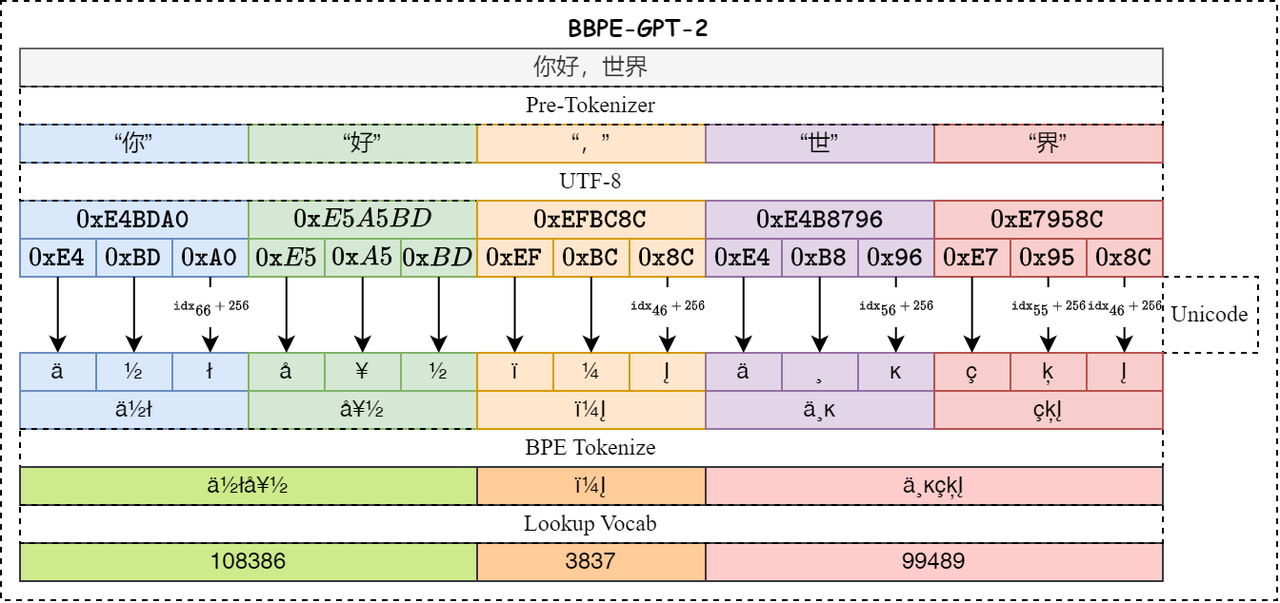
llama.cpp中所指的BPE(Byte-Pair-Encoding)准确地说应该是BBPE(Byte-Level-Byte-Pair-Encoding),是一种字节级别的字节对编码方式,主要用于自然语言处理中的文本压缩和词表构建。 BPE 是一种基于字节对的编码方法,它通过迭代地合并最频繁出现的字节对来构建词汇表。在分词过程中,BPE 会根据词汇表中的字节对来分割文本。

1 | def bytes_to_unicode(): |
Unicode 符号表


经过BBPE编码后的词表保存在 vocab.json 文件中,详细内容如下:
merges.txt文件定义了字节合并的规则,文件前16行内容如下:
1 | Ġ Ġ |
具体来说,BPE通过将文本中的频繁出现的字节对(Byte Pair)替换为一个新的符号,从而减少词汇表的大小。例如,在一个文本中,如果"the"这个词出现得非常频繁,那么BPE可能会将"the"替换为一个新的符号,比如"$"。这样,在后续的处理中,就可以用一个符号来表示"the"这个词,从而减少词汇表的大小。 在llama.cpp中,BPE的实现主要涉及到以下几个步骤:
- 构建初始词汇表:首先,从文本中提取出所有的字节,并将它们作为初始词汇表。
- 计算字节对频率:对于每个字节对,计算它们在文本中出现的频率。
- 选择最高频率的字节对:选择出现频率最高的字节对,并将其替换为一个新的符号。
- 更新词汇表:将新的符号添加到词汇表中,并更新文本中所有出现该字节对的地方。
- 重复步骤2-4,直到达到某个停止条件,例如词汇表大小达到某个阈值或者字节对频率不再变化。 通过不断地重复上述步骤,BPE可以将文本中的词汇表压缩到一个较小的规模,从而提高模型的效率和性能。同时,BPE也可以用于构建语言模型的词表,从而提高模型的准确性和泛化能力。
UGM
UGM(UniGram) 是一种基于 Unigram 的分词方法,它通过学习单词的出现频率来构建词汇表。在分词过程中,UGM 会根据词汇表中的单词来分割文本。 直观地说,我们的目标是从训练语料库中构建一个相当广泛的种子词汇表。这个初始步骤至关重要,因为它是后续词汇扩展的基础。
然后,我们反复执行以下程序,直到词汇表 |V| 的大小达到所需的规模。
- 在词汇集固定的情况下,我们使用期望最大化 (EM) 算法优化概率分布 p(x)。该算法允许有效地估计模型参数,确保模型很好地拟合数据。
- 对于每个子词 xi,我们计算 lossi,它表示当子词 xi 从当前词汇表中排除时总体似然 L 减少的可能性。这个指标为词汇表中每个子词的重要性提供了有价值的见解。
- 我们根据 lossi 的值对符号进行排序,并保留前 η% 的子词(例如,η 设为 80%)。需要注意的是,我们始终保留由单个字符组成的子词,以防止出现任何词汇表外的情况。通过这样做,我们确保词汇表仍然全面,能够表示广泛的文本。
RWKV
RWKV(Receptance-Weight-Key-Value) Tokenizer 是一种特定于RWKV架构的分词方法,具体特点和应用场景可能因模型的不同而有所差异。 RWKV-World 系列模型使用 rwkv_vocab_v20230424 分词器,具体的文件是 rwkv_vocab_v20230424.txt,可以在 RWKV-主库的 RWKV-v5/tokenizer(opens in a new tab) 目录中找到 。 rwkv_vocab_v20230424 分词器合并了以下分词器的词汇表,并手动为非欧洲语言选择了 token:
- GPT-NeoX-20B(opens in a new tab)
- GPT2(opens in a new tab)
- cl100k_base of tiktoken(opens in a new tab)
- Llama2(opens in a new tab)
- Bloom(opens in a new tab)
分词器通过 Trie(前缀树)实现,在提高速度的同时保持简洁性。编码过程是通过从左到右匹配词汇表中最长的元素与输入字符串进行的。 分词器的词汇量大小为 V = 65536,编号从 0 到 65535,token 按其在字节中的长度排列。 以下是简要概述:
token 0:表示文本文档之间的边界,称为<EOS>或<SOS>。此 token 不编码任何特定内容,仅用于文档分隔。token 1-256:由字节编码组成(tokenk 编码字节 k−1),其中 token 1-128 对应于标准 ASCII 字符。token 257-65529:至少具有 2 个 UTF-8 字节长度的 token,包括单词、前缀和后缀、带重音的字母、汉字、韩文、平假名、片假名和表情符号。例如,汉字被分配在 token 10250 至 18493 之间。token 65530-65535:预留 token,供将来使用。
不同的分词器在不同的语言和任务中具有不同的表现,选择合适的分词器对于模型的性能和效果至关重要。在 llama.cpp 中,根据具体的需求和模型,可以灵活选择使用不同的分词器来对文本进行处理。
Embedding
在自然语言处理中,词嵌入(Word Embedding)是将词汇表中的单词或短语映射到实数向量的技术。这些向量通常具有较低的维度,并且在向量空间中具有一定的语义和语法关系。词嵌入在许多自然语言处理任务中都有广泛的应用,例如文本分类、情感分析、机器翻译等。 在 llama.cpp 中,词嵌入的实现方式可能会因模型的不同而有所差异。一般来说,词嵌入可以通过以下几种方式实现:
- 基于预训练模型的词嵌入:使用已经在大规模文本上训练好的词嵌入模型,例如 Word2Vec、GloVe 等。这些模型通常具有较高的语义表示能力,可以直接将输入的单词转换为对应的词嵌入向量。
- 随机初始化的词嵌入:在模型训练过程中,随机初始化词嵌入向量,并通过反向传播算法不断调整这些向量,以使其能够更好地表示单词之间的语义关系。
- 基于上下文的词嵌入:通过分析单词在上下文中的出现情况,来学习词嵌入向量。这种方法通常需要在模型中添加一些额外的模块,例如卷积神经网络或循环神经网络,以捕捉上下文信息。 无论采用哪种方式,词嵌入的目的都是将单词转换为具有语义和语法信息的向量,以便模型能够更好地处理和理解自然语言。在 llama.cpp 中,词嵌入通常是模型的输入之一,模型会根据输入的词嵌入向量来进行后续的计算和预测。
Get Embedding Matrix
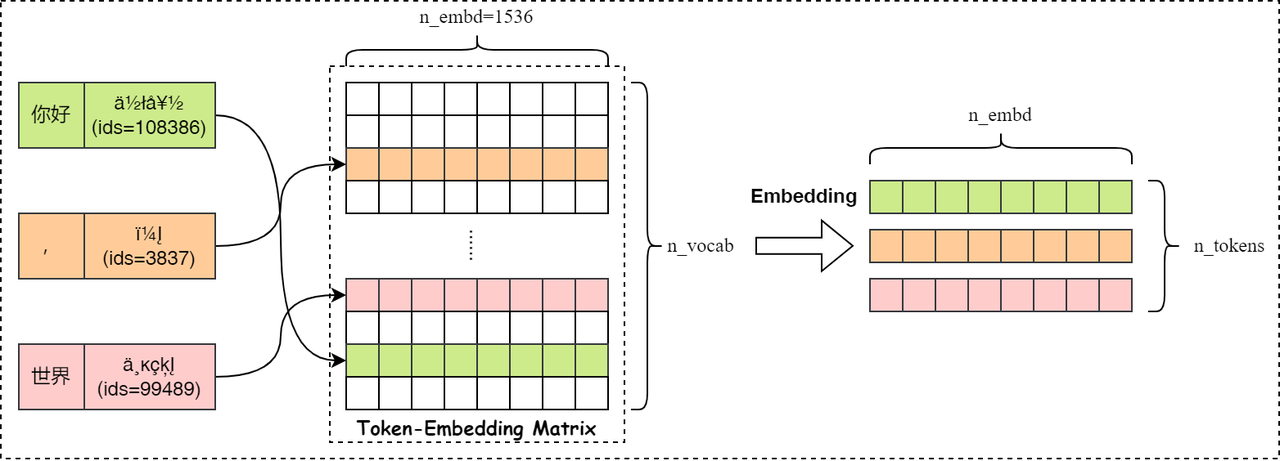
llama.cpp中模型对应的嵌入矩阵存储参数在GGUF格式的文件中,通过 token_embd关键字解析嵌入矩阵的内容,如下代码创建了嵌入矩阵 model.tok_embd:
1 | model.tok_embd = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, 0); |
Get Token Embedding Vector
首先创建一个新的由整数构成的一维张量,称作 inp_tokens,用于保存词元的索引数值。然后调用 ggml_set_input函数将张量标志设置为 GGML_TENSOR_FLAG_INPUT。最后调用 ggml_get_rows 函数创建一个新的张量操作节点GGML_OP_GET_ROWS,实现从词元嵌入矩阵中获取具体索引值得词原嵌入向量, 然后创建一个存储 token_id 的张量(lctx.inp_tokens),根据 token_id 和 嵌入矩阵(model.tok_embd) 调用 ggml_get_rows 函数实现token的嵌入矩阵(inpL)的获取,详细代码如下: 只有在编码解码阶段采用更新inp_tokens张量的实际值。
1 | lctx.inp_tokens = ggml_new_tensor_1d(ctx, GGML_TYPE_I32, batch.n_tokens); |
整个嵌入过程如下图所示: