ggml介绍-llama.cpp
概述
llama.cpp 使用 ggml 张量加速库,这是一个纯 C++ 实现的张量加速库。

GGUF
GGUF(GPT-Generated-Unified-Format) 是一种文件格式,用于存储使用 GGML 进行推理的模型以及基于 GGML 的执行器。GGUF 是一种二进制格式,旨在快速加载和保存模型,并且易于读取。模型传统上是使用 PyTorch 或其他框架开发的,然后转换为 GGUF 以用于 GGML。 它于 2023 年 8 月推出,是 GGML、GGMF 和 GGJT 的后续文件格式,旨在通过包含加载模型所需的所有信息来做到明确无误。它还被设计为可扩展的,因此可以在不破坏兼容性的情况下将新信息添加到模型中。
历史现状
目前,有三种用于大型语言模型的GGML文件格式在流传。
- GGML (GPT-Generated-Model-Layout)(非正式版本) 基线格式,无版本控制或对齐。
- GGMF (GPT-Generated-Model-Format)(第一个版本) 与GGML相同,使用 Protobuf 进行序列化,但增加了版本控制,适用于需要考虑文件版本兼容性的场景。仅存在一个版本。
- GGJT (GPT-Generated-JIT) 使张量对齐以便与需要对齐的 mmap 一起使用。v1、v2 和 v3 彼此相同,但后两个版本使用了与先前版本不兼容的不同量化方案。专注于性能优化,特别是在使用内存映射时的性能,但牺牲了与旧版本的兼容性。
GGUF 实际上是基于 GGJT 的格式进行优化的,并解决了 GGML 当初面临的问题,包括:
- 可扩展性:轻松为 GGML 架构下的工具添加新功能,或者向 GGUF 模型添加新 Feature,不会破坏与现有模型的兼容性。
- 对 mmap(内存映射)的兼容性:该模型可以使用 mmap 进行加载,实现快速载入和存储。
- 易于使用:模型可以使用少量代码轻松加载和存储,无需依赖的 Library,同时对于不同编程语言支持程度也高。
- 模型信息完整:加载模型所需的所有信息都包含在模型文件中,不需要额外编写设置文件。
- 有利于模型量化:GGUF 支持模型量化(2位、4 位、8 位、F16),在 GPU 变得越来越昂贵的情况下,节省 vRAM 成本也非常重要。
历史版本
- V1 GGUF文件格式的初始版本
- V2 大多数可计数的值(长度等)已从 uint32 更改为 uint64,以便将来能够支持更大的模型。
- V3 添加对大端设备的支持。
文件结构
如下代码是gguf文件的结构体,总的结构如下:
1 | struct gguf_context { |
其中,文件头结构如下,包含魔术数、版本信息、tensor的数量和KV字典的数量等信息:
1 | struct gguf_header { |
KV字典的结构如下,包含key值、value值和数据类型等信息:
1 | struct gguf_kv { |
tensor结构体如下,包括tensor名、维度、类型和指针等信息:
1 | struct gguf_tensor_info { |
如下图所示,是 GGUF 文件格式的结构图:

标准化的键值对(gguf_kv)
以下键值对已实现标准化。随着未来更多用例的出现,此列表或许会有所增加。在条件允许的情况下,名称会与原始模型定义保持一致,以方便在两者之间进行映射。 并非所有这些都是必需的,但都建议使用。必需的键已高亮标注。对于被省略的键值对,读者应假定其值未知,并依据具体情况使用默认值或报错。 社区能够开发自身的键值对来承载额外的数据。不过,这些键值对应当运用相关的社区名称进行命名空间的划分,以规避冲突。例如,rustformers 社区可以将“rustformers.”作为其所有键的前缀。倘若某个特定社区的键值被广泛运用,那么它有可能会被提升为标准键值对。 依照惯例,除非另有说明,大多数计数/长度/等均为 uint64 类型。这是为了将来能够支持更大的模型。某些模型可能对其值采用 uint32 类型;建议读者同时支持这两种类型。
可以通过如下网页编辑器查看模型文件结构: gguf-editor
LLM
在下文中,llm 用于代替特定大型语言模型架构的名称。例如,llama 代表 LLaMA,mpt 代表 MPT,等等。如果在某个架构的章节中提到,则该架构需要该键,但并非所有架构都需要所有键。请参阅相关章节了解更多信息。
Tokenizer
以下键用于描述模型的分词器。建议模型作者尽可能支持这些键,因为这将允许支持的执行器获得更好的分词质量。
tokenizer.ggml.model:分词器模型名称- llama: SPM(LLaMA tokenizer based on byte-level BPE with byte fallback);
- bert: WPM (BERT tokenizer based on WordPiece);
- gpt2:BPE(GPT-2 tokenizer based on byte-level BPE);
- t5 : UGM (T5 tokenizer based on Unigram)
- rwkv: RWKV tokenizer based on greedy tokenization;
tokenizer.ggml.pre: 预分词器名称 只有使用BPE类型的模型才有预分词器的配置项。- llama3
tokenizer.ggml.tokens: 模型使用的词元 ID 索引的词原列表tokenizer.ggml.scores:词元的概率值 如果存在,则为每个词元的得分/概率。如果不存在,则假设所有词元具有相同的概率。如果存在,则其长度和索引必须与词元相同。tokenizer.ggml.token_type:词元类型 如果存在,则其长度和索引必须与词元相同。- 0:未定义;
- 1:正常;
- 2:未知;
- 3:控制;
- 4:用户定义;
- 5:未使用;
- 6:字节;
标准化的张量名称(gguf_tensor_info)
位于文件gguf-py/gguf/constants.py中,为最小化复杂度并最大化兼容性,建议使用Transformer架构的模型对其张量使用以下命名约定:
Base layers
AA.weight 或 AA.bias,其中AA可以是:
token_embd:词嵌入层position_embd:位置嵌入层output_norm:输出归一化层output:输出层
Attention and feed-forward layer blocks
blk.N.BB.weight 或 blk.N.BB.bias,其中N表示某层所属的块编号,而BB可以是:
attn_norm:注意力归一化层attn_norm_2:注意力归一化层
命名规范
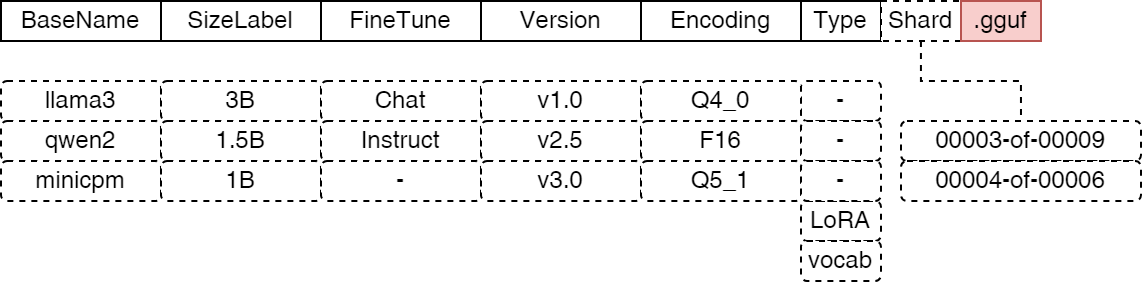
GGUF 遵循 <基础名称><尺寸标签><微调><版本><编码><类型><分片>.gguf 的命名约定,其中每个组件如有存在则以 - 分隔。最终目标是让人们能够一目了然地获取模型最重要的细节。由于现有 gguf 文件名的多样性,它并非旨在完全适用于字段解析。
ggml_tensor
参考源码对tensor的结构定义如下:
1 | struct ggml_tensor { |
基本属性
type
包含张量元素的原始类型,例如GGML_TYPE_F32表示张量内存储的每个元素是32bit的浮点数。详细的支持类型列表如下:
1 | enum ggml_type { |
backend
该字段已经被弃用,不推荐使用,主要是为了和旧版本保持兼容,之前负责管理和存储张量数据的后端设备,目前建议使用 buffer字段中的type属性来确定数据存储位置。
1 | enum ggml_backend_type { |
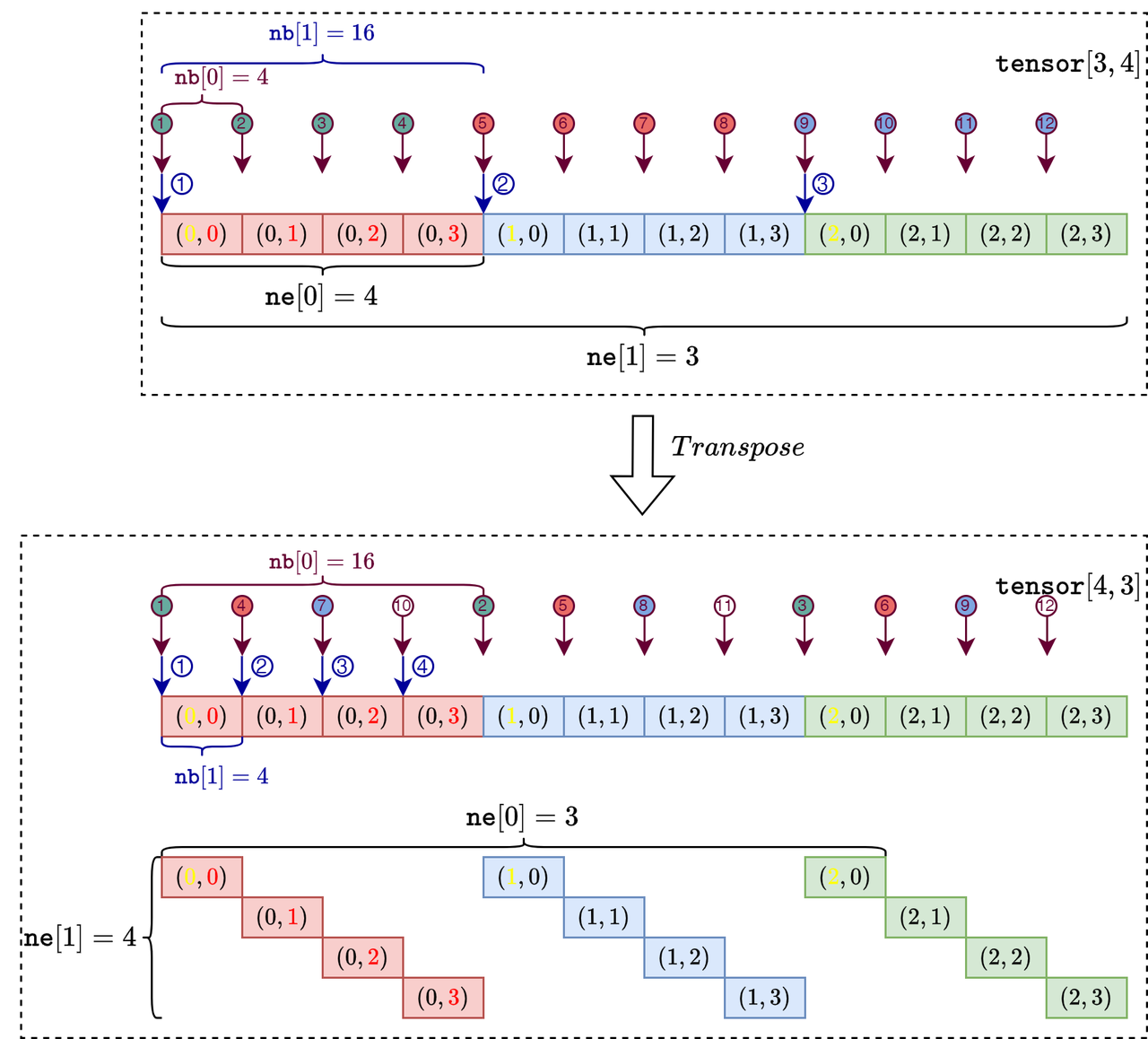
ne
该字段是包含每个维度元素的数量的数组,由于ggml采用行主序,意味着\(\mathtt{ne}[0]\)表示每一行的元素个数,\(\mathtt{ne}[1]\)表示每一列的元素个数。其中,支持的最大维度为4。
nb
该字段包含每个维度步幅(单位byte)的数组,即为每个维度中连续元素之间的字节数。
- 第一个维度的步幅计算为原始元素的字节大小,通常使用ggml_type_size函数获得: \[\mathtt{nb}=\text{ggml_type_size(type)}\]
- 第二个维度的步幅计算考虑了阻塞(可能是为了性能和对齐)和填充: \[\mathtt{nb}[1] = \mathtt{nb}[0] * \Big(\frac{\mathtt{ne}[0]}{\text{ggml_blck_size(type)}}\Big) + \text{padding}\]
- 后续维度的步幅计算为 \[\mathtt{nb}[i] = \mathtt{nb}[i-1] * \mathtt{ne}[i-1]\]
示例
假设tensor的数据类型为 float32,shape为\([2,3,4]\),则下图描述了\(\mathtt{ne}\)和\(\mathtt{nb}\)的计算过程。其中,ne={4,3,2}, nb={4,16,48}:

数据结构中使用步幅的目的是为了执行某些张量运算时无需数据拷贝操作。例如,对一个二维矩阵进行转置操作就是将行转换为列,在ggml中可以通过简单地翻转 ne 和 nb 并指向相同的基础数据来实现,详细代码如下:
1 | struct ggml_tensor * ggml_transpose( |
在上述函数中,result 是一个新张量,它被初始化为指向与源张量 a 相同的多维数字数组。通过交换 ne 中的维度和 nb 中的步幅,实现了转置操作而无需复制任何数据。 例如,张量\(K=[3,4]\),则其转置为\(K^T=[4,3]\),通过交换 ne 和 nb 实现的转置操作流程如下图:
张量计算
如前所述,有些张量表示存储的数据,而另一些张量则表示其他张量之间运算的理论结果。
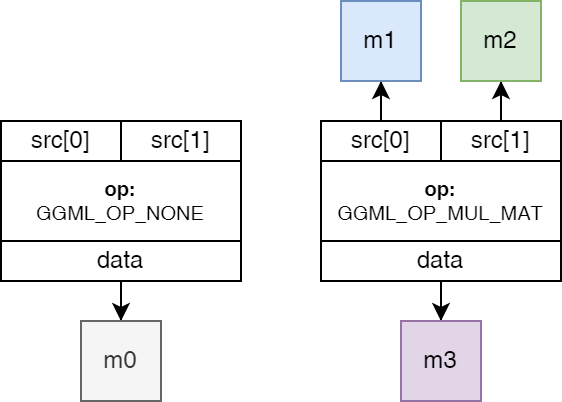
op
指定创建此张量的操作(矩阵乘、加法或激活等),如果设置为GGML_OP_NONE,表明该张量持有数据,否则表明是某个运算的结果值。GGML_OP_MUL_MAT意味着该张量不持有数据,而仅代表两个其他张量之间矩阵乘法的结果。
op_params
存储生成张量的操作 (op) 的特定参数。例如,如果 op 是卷积,则 op_params 可能包含步长、填充和内核大小等。使用 int32_t 可能是确保适当的内存对齐。
flags
存储与张量关联的标志或属性。这些可能指示张量是否为常量、是否需要梯度计算或是否为另一个张量的视图等信息。
1 | enum ggml_tensor_flag { |
src
指向源张量的指针数组。这表示计算图中的依赖关系。例如,两个张量相加的结果将在该数组中包含指向两个输入张量的指针。目前支持的最大输入数量为10。
示例
可以使用矩阵乘法函数说明上述概念:
1 | struct ggml_tensor * ggml_mul_mat( |
在上述函数中,result 不包含任何数据,它仅仅代表着 a 和 b 相乘的理论结果。
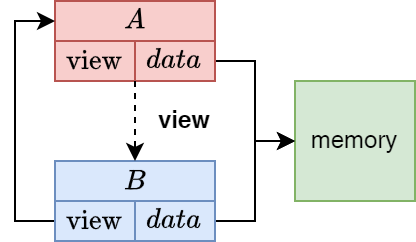
张量视图
view_src
如果此张量是另一个张量的视图,则此指针指向原始(源)张量。视图与源张量共享数据,而无需创建副本。
view_offs
如果此张量是视图,则此字段表示从源张量数据开始到此视图数据开始的字节偏移量。
data
指向实际张量数据的指针。根据实现的不同,这可能直接指向 buffer 或 view_src 张量中的特定位置。
其它字段
name
一个字符串,用于给张量命名,这对于调试和可视化很有帮助
extra
一个通用指针,用于存储额外的数据,很可能用于后端特定的信息或扩展(for ggml-cuda.cu)。
padding
填充以确保适当的内存对齐或容纳结构体的潜在未来添加,而不会破坏 ABI 兼容性.
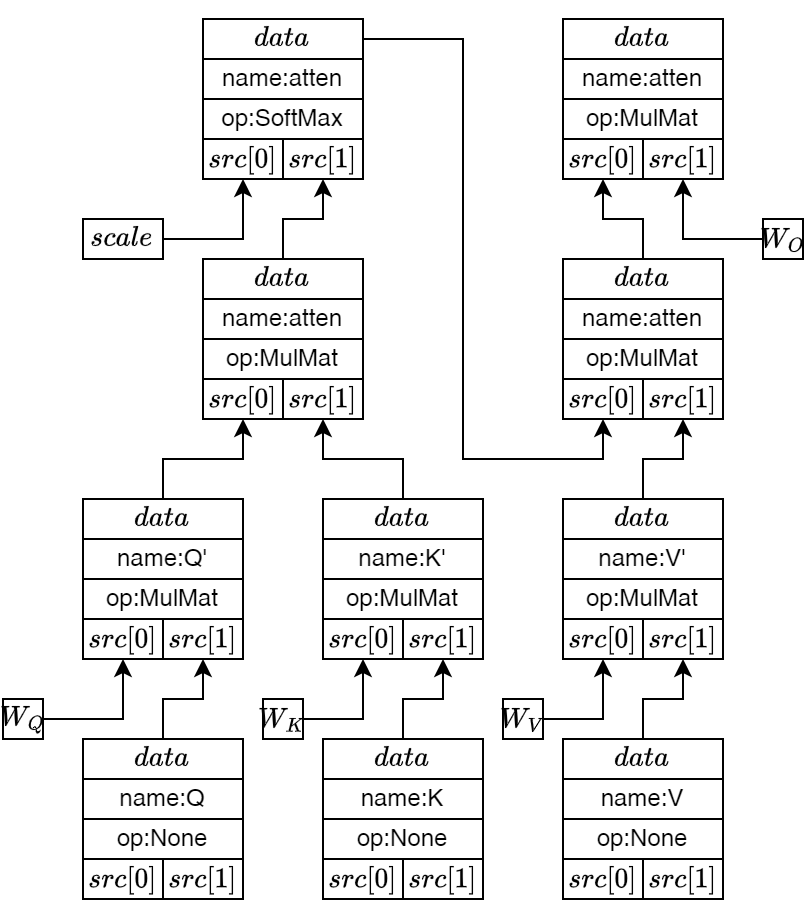
ggml_tensor的应用
llama.cpp构建网络图的方式就是以tensor对象为基本节点,以链表的形式构建网络的。如下图所示,构建了一个简单的 Attention 图。