关于大语言模型的采样算法分析-llama.cpp
概述
LLM的原始输出是一个 logits 列表,该列表中的每个元素对应一个词元的预测概率,基于它们选择下一个预测的token, 这个过程称为采样。目前llama.cpp存在多种采样方法可供选择,它们适用于不同的应用场景。 例如,在一些自然语言处理任务中,可能会采用贪心采样(Greedy Sampling)方法,即总是选择具有最高概率的token作为下一个 token。 这种方法简单直接,但可能会导致生成的文本缺乏多样性。 另一种常见的采样方法是随机采样(Random Sampling),它会根据 token 的概率分布进行随机选择。虽然这种方法增加了生成文本的多样性, 但也可能引入一些不太合理的选择。 为了在多样性和合理性之间取得平衡,还有一些更复杂的采样方法,如基于温度的采样(Temperature-based Sampling)。通过调整温度参数, 可以控制概率分布的平滑程度,从而影响采样的随机性。 此外,还有一些基于束搜索(Beam Search)的采样方法,它会同时考虑多个可能的序列,并根据一定的评估标准选择最优的序列作为输出。 不同的采样方法在不同的场景下具有各自的优势和局限性,选择合适的采样方法对于生成高质量的文本至关重要。
Sampling Chain
llama.cpp中使用采样链的框架来组合不同的采样算法,采样链路的初始化流程如下图所示:
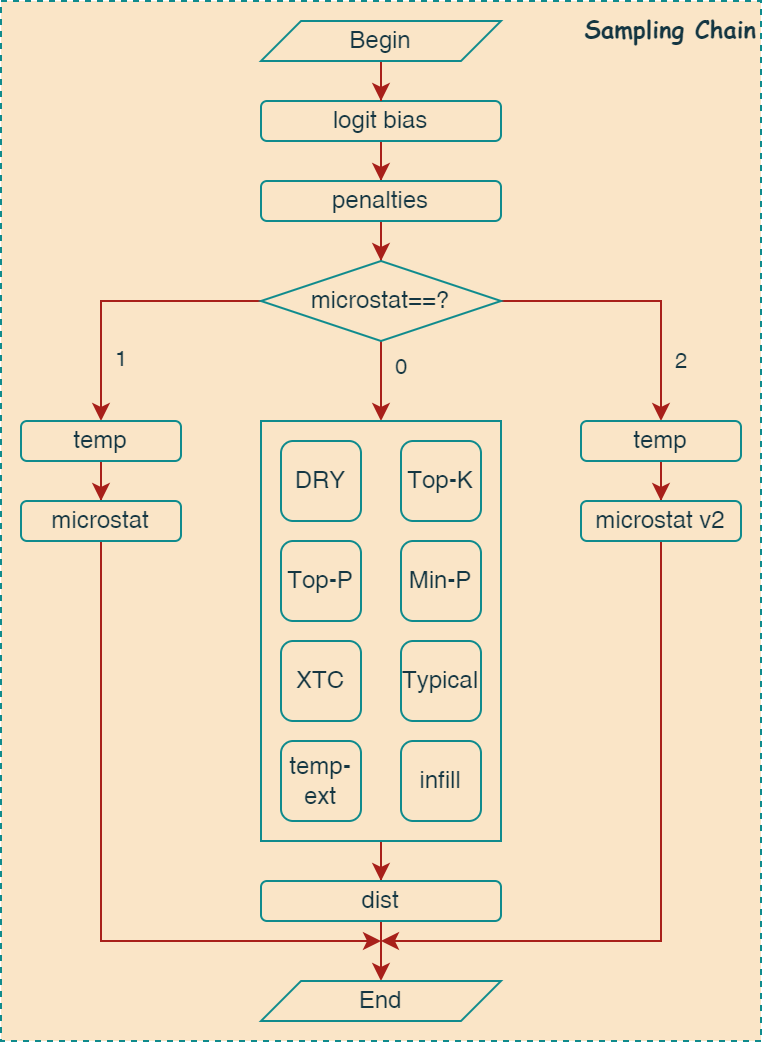
1 | sampler chain: logits -> logit-bias -> penalties -> dry -> top-k -> typical -> top-p -> min-p -> xtc -> temp-ext -> dist |
首先,logit_bias 和 penalties 采样会默认加入到采样链中,然后根据 microstat 参数的值,选择不同的采样算法加入到链路中。 如果 microstat 参数的值为0,则通过 Top-K 和 Top-P 等一系列采样算法从输出的 logit 分布中截断一部分token,组成新的 候选集合。最后再基于候选集合使用dist采样进行随机采样。如果数值为1或2,则使用microstat v1或microstat v2采样算法。
如下代码所示,调用采样链函数时,会逐个调用每个注册的采样器。
1 | static void llama_sampler_chain_apply(struct llama_sampler * smpl, llama_token_data_array * cur_p) { |
Output Token Struct
输出的logits数组结构如下:
1 | typedef struct llama_token_data_array { |
每个输出token的结构如下:
1 | typedef struct llama_token_data { |
基本采样算法
基本采样算法的思路就是通过设定一个固定的阈值对logits分布进行截断,从而生成一个候选集合。然后再对这个候选集合进行随机采样,下面将简单介绍这些基本采样算法的思路。
Greedy Sampling
贪婪采样是一种直接的方法,每次选择概率最高的 token 作为下一个生成的 token。下图简单描述了其算法思路:
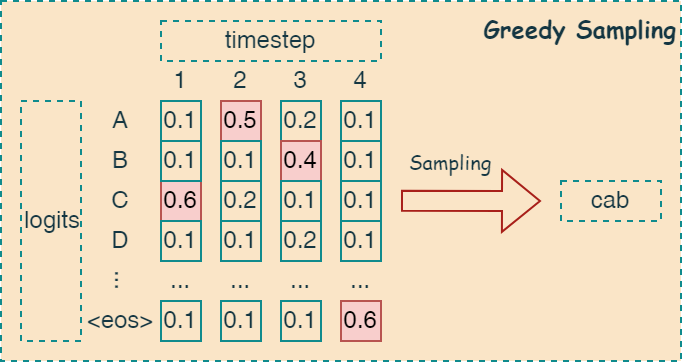
如下代码所示,通过比较 logit 数组中的数值,将最大值的索引保存到 selected 字段中。
1 | cur_p->selected = 0; |
Dist Sampling
离散概率分布采样是一种基于概率分布的采样算法,即从给定的概率分布中采样一个 token 的索引。 一般不会单独使用,需要配合 top-k , top-p 等采样算法一起使用。 因此在采样过程中,概率高的token索引会以较高的概率采样到,概率小的token索引会以较小的概率采样到。 下图可以很好得描述其算法思路:
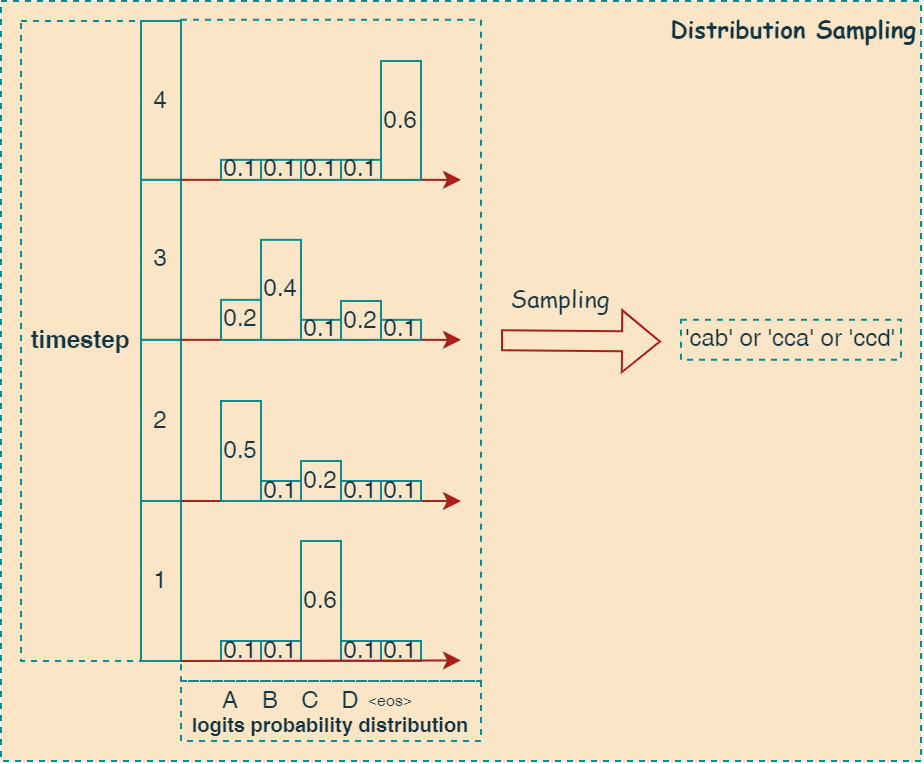
如下代码所示,实现了一个基于概率分布的 token 采样器。它首先将 logits 转换为概率分布,然后根据这个概率分布随机选择一个 token。 其中 cur_p 包含模型预测的下一个 token 的概率分布。
1 | static void llama_sampler_dist_apply(struct llama_sampler * smpl, llama_token_data_array * cur_p) { |
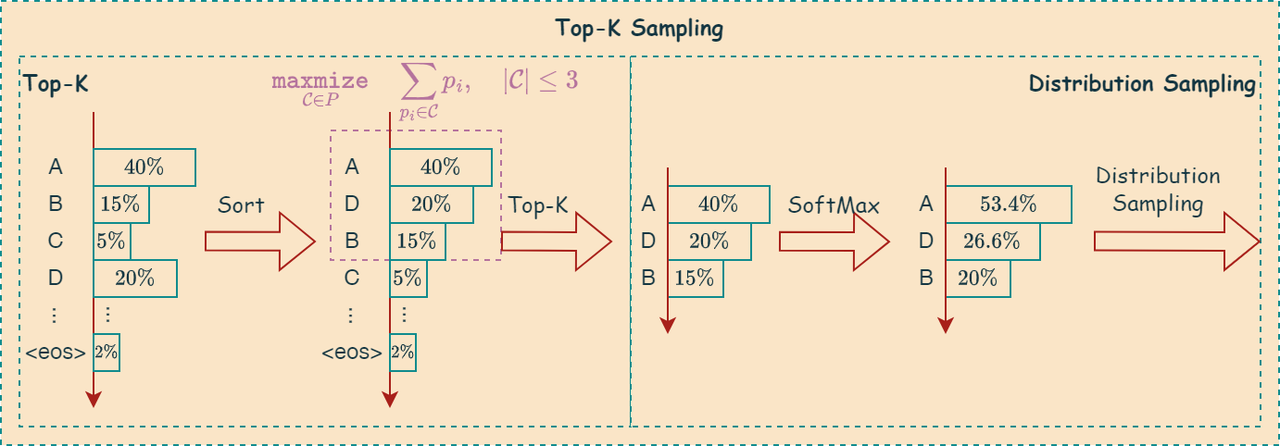
Top-k Sampling
Top-K 采样是一种用于从概率分布中生成样本的策略,其核心思想是:只从概率最高的 K 个候选项中进行采样。 这样做的目的是在保证生成文本多样性的同时,避免选择概率过低的词,从而提高生成文本的质量和流畅度。
\[\large \underset{\mathcal{C} \in P}{\mathtt{maxmize}} \quad \sum_{p_i\in\mathcal{C}}p_i, \quad |\mathcal{C}|\le \mathtt{k}\]
算法步骤
Top-K 采样算法的步骤如下:
步骤 1:获取概率分布
在生成下一个词时,LLM 会根据当前上下文计算词汇表中每个词的概率。假设词汇表大小为 \(\mathtt{v}\) , 我们得到一个概率分布: \(P=[p_1,p_2,...,p_{\mathtt{v}}]\),其中 \(p_i\) 表示词汇表中第 i 个词的概率。
步骤 2:选择 Top-K 候选项
从概率分布 \(P\) 中选择概率最高的 K 个词,构成一个候选集合
Top-K Vocabulary。 例如,如果 K=5,我们就选择概率最高的 5 个词。步骤 3:重新归一化概率
将 Top-K 候选集合中词的概率进行重新归一化,使其总和为 1。 这样做的目的是确保采样仍然是一个有效的概率分布。
步骤 4:采样
根据重新归一化后的概率分布,从 Top-K 候选集合中随机采样一个词作为生成的下一个词。
算法图解
如下图所示,描述了上述算法:
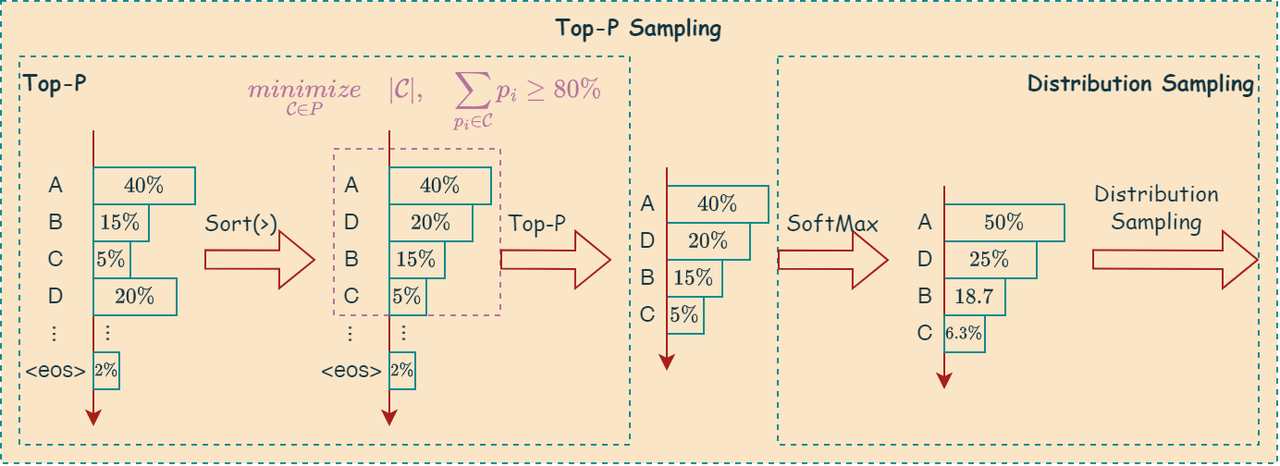
Top-p Sampling
Top-P 采样也是一种从概率分布中生成样本的策略,其核心思想是:动态地选择一个最小的候选集合, 使得该集合中所有候选项的概率之和大于或等于一个预先设定的阈值 \(\mathtt{p}\)。 这样做的目的是在保证生成文本多样性的同时, 避免选择概率过低的词,并且能够根据不同的概率分布自适应地调整候选集合的大小。
\[\underset{\mathcal{C} \in P}{minimize} \quad |\mathcal{C}|, \quad \sum_{p_i\in\mathcal{C}}p_i \ge \mathtt{p}\]
算法步骤
Top-P 采样算法的步骤如下:
步骤 1:获取概率分布
与 Top-K 采样类似,在生成下一个词时,LLM 会根据当前上下文计算词汇表中每个词的概率。 假设词汇表大小为 \(\mathtt{v}\) ,我们得到一个概率分布:\(P=[p_1,p_2,...,p_{\mathtt{v}}]\),其中 \(p_i\) 表示词汇表中第 i 个词的概率。
步骤 2:排序概率
将概率分布 \(P\) 中的概率按降序排列。
步骤 3:选择候选集合
从概率最高的词开始,依次累加其概率,直到累加概率的和大于或等于预先设定的阈值 \(\mathtt{p}\)。 将这些词构成候选集合
Top-P vocabulary。步骤 4:重新归一化概率
将 Top-P 候选集合中词的概率进行重新归一化,使其总和为 1。
步骤 5:采样
根据重新归一化后的概率分布,从 Top-P 候选集合中随机采样一个词作为生成的下一个词。
算法图解
如下图所示,描述了上述算法:
算法代码
相关代码如下:
1 | static void llama_sampler_top_p_apply(struct llama_sampler * smpl, llama_token_data_array * cur_p) { |
优点与缺点
优点
- 自适应候选集合大小: 与 Top-K 采样固定候选集合大小不同,Top-P 采样可以根据不同的概率分布动态调整候选集合的大小。 当概率分布比较集中时,候选集合较小;当概率分布比较分散时,候选集合较大。
- 平衡多样性和质量: 通过调整 p 值,可以控制生成文本的多样性。较大的 p 值会增加多样性,较小的 p 值会降低多样性。
- 避免低概率词: Top-P 采样可以有效避免选择概率过低的词,从而提高生成文本的质量。
缺点
- 计算效率: Top-P 采样需要排序概率和累加概率,计算效率略低于 Top-K 采样。
- p 值选择: p 值的选择需要根据具体任务和数据集进行调整,没有一个通用的最佳值。
适用场景
Top-P 采样算法适用于需要生成高质量、多样性文本的场景,尤其适用于概率分布不均匀的场景。例如:
- 故事生成: 生成更富有想象力和情节的故事。
- 开放域对话: 生成更自然、多样的对话回复。
- 代码生成: 生成更准确、多样的代码片段。
Min-P Sampling
Min-p采样,也称为 Tail Sampling,是一种用于从概率分布中生成样本的策略,它的核心思想是:设置一个概率阈值\(p\), 只保留概率大于等于\(p\)的候选项,然后从这些保留的候选项中进行采样;如果所有候选项的概率都小于 \(p\),则从所有候选项中进行采样。 这样做的目的是在保证生成文本多样性的同时,尽可能避免选择概率过低的词,并且在概率分布较为平坦时也能进行有效采样。
算法步骤
Min-p 采样算法的步骤如下:
步骤 1:获取概率分布
与之前的采样方法类似,在生成下一个词时,LLM 会根据当前上下文计算词汇表中每个词的概率。假设词汇表大小为 \(\mathtt{v}\) ,我们得到一个概率分布:\(P=[p_1,p_2,...,p_{\mathtt{v}}]\),其中 \(p_i\) 表示词汇表中第
i个词的概率。步骤 2:设置概率阈值p
预先设定一个概率阈值 \(\mathtt{p}\) 。
步骤 3:选择候选集合
遍历概率分布 \(V\) ,将所有概率大于 \(\mathtt{p}\) 的词加入候选集合
Candidate Vocabulary。步骤 4:判断候选集合是否为空
- 如果候选集合不为空,则进入步骤
5。 - 如果候选集合为空,则将所有词汇表中的词都加入候选集合,即
Candidate Vocabulary= \(V\) 。
- 如果候选集合不为空,则进入步骤
步骤 5:重新归一化概率
将候选集合
Candidate Vocabulary中词的概率进行重新归一化,使其总和为1。步骤 6:采样
根据重新归一化后的概率分布,从候选集合
Candidate Vocabulary中随机采样一个词作为生成的下一个词。
算法图解
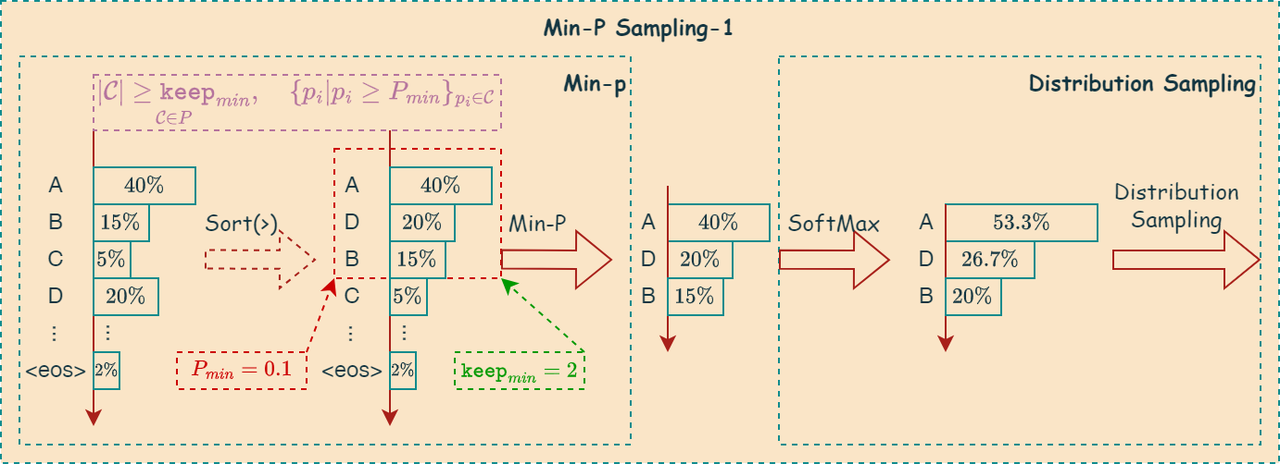
llama.cpp中的 Min-p 采样算法需要配置\(P_{min}\)和\(\mathtt{keep}_{min}\)两个参数,其中\(P_{min}\)用于控制候选集合保留概率值大于阈值的token数量,\(\mathtt{keep}_{min}\)用于控制候选集合保留的最小token元素数量。
在llama.cpp中, \(P_{min}\)概率阈值计算方式如下:
\[P_{min}=P_{max}+\log(P_{thd})\]
算法可以用如下公式表示:
\[\large\underset{\mathcal{C}\in P}{|\mathcal{C}|\ge \mathtt{keep}_{min}}, \quad\{p_i|p_i\ge P_{min}\}_{p_i \in \mathcal{C}}\]
候选集合元素数量充足
当logits集合中的元素概率大于等于\(P_{min}\)的数量超过或等于\(\mathtt{keep}_{min}\)时,基于该候选集合的分布进行toeken采样。
采样时,不需要对logits集合进行排序,直接遍历所有元素与\(P_{min}\)对比,从而提升性能。
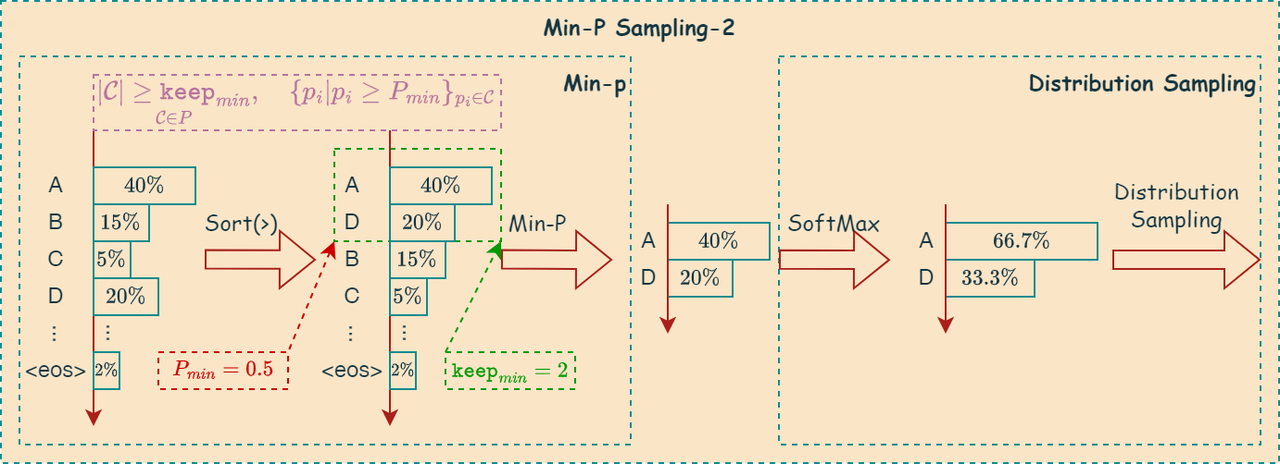
候选集合元素数量不足
当logits集合中的元素概率值大于等于\(P_{min}\)的token数量不足\(keep_{min}\)时,则使用类似Top-K的方式,将集合中概率较大的前\(keep_{min}\)个概率值作为候选集合,然后再进行采样。
优点与缺点
优点
- 避免低概率词: Min-p 采样可以有效避免选择概率过低的词,从而提高生成文本的质量。
- 处理平坦分布: 当概率分布较为平坦时,Min-p 采样能够保证采样仍然有效进行,避免候选集合为空的情况。
- 简单易实现: Min-p 采样的算法逻辑相对简单,易于实现。
缺点
- p 值选择: p 值的选择需要根据具体任务和数据集进行调整,没有一个通用的最佳值。 过大的 p 值可能导致候选集合为空,过小的 p 值可能无法有效过滤低概率词。
- 可能忽略重要信息: 如果一些重要词的概率较低,但低于阈值 p,可能会被 Min-p 采样忽略。
适用场景
Min-p 采样算法适用于需要生成高质量文本,并且希望避免选择低概率词的场景。例如:
- 机器翻译: 生成更准确、自然的译文。
- 文本摘要: 生成更简洁、连贯的摘要。
- 对话生成: 生成更自然、流畅的对话回复,避免出现不相关的词语。
XTC Sampling
算法步骤
XTC 算法步骤如下:
寻找最后一个高概率 token 的位置
遍历 token 及其概率,找到最后一个概率大于等于
threshold的 token 的位置pos_last。截断操作
如果从
pos_last到数组末尾的 token 数量大于等于min_keep,并且pos_last大于 0 (意味着至少存在一个高概率 token),则只保留从pos_last开始到数组末尾的 token。这意味着,xtc 采样会移除pos_last之前的所有 token,包括那些概率高于阈值的 token,而保留pos_last及其之后的所有 token,无论它们的概率是否高于阈值。如果不满足上述条件,则不进行截断。
算法图解
如下图所示,描述了上述算法:
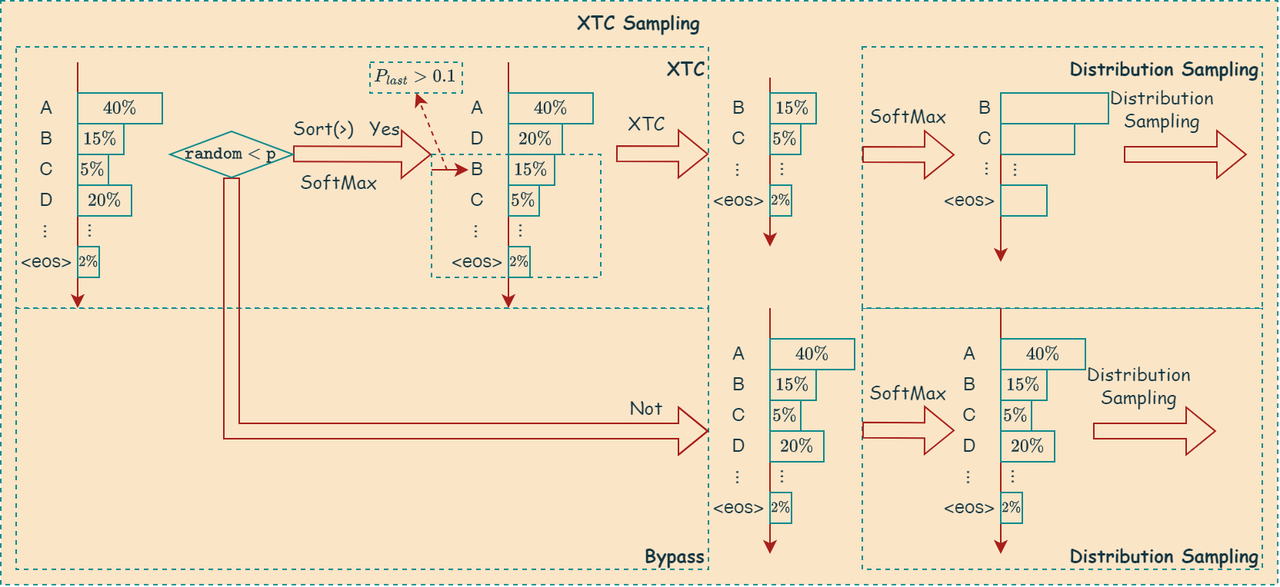
XTC采样的这种行为看似反直觉,但其目的是为了实现一种特殊的采样策略,这种策略可以概括为:
聚焦于高概率token的边界
xtc 采样并不像 Top-k 或 Top-p 采样那样直接选择概率最高的 k 个或累积概率达到 p 的 token。相反,它关注的是概率分布中从高概率 token 过渡到低概率 token 的边界区域。通过只保留最后一个高概率 token 及其之后的 token,xtc 采样试图捕捉这种边界信息。
增加采样多样性
移除大部分高概率 token 的一个重要目的是为了增加采样的多样性。如果总是选择概率最高的 token,生成的文本可能会过于单一和重复。通过保留最后一个高概率 token 及其之后的低概率 token,xtc 采样引入了一定的随机性,使得生成的文本更具多样性。
一种特殊的截断策略
XTC 采样可以看作是一种特殊的截断策略,它不同于 Top-k 或 Top-p 等常见的截断方法。它不是直接截断概率低的 token,而是通过找到最后一个高概率 token 的位置来确定截断点,然后保留截断点及其之后的所有 token。这种策略具有一定的特殊性和针对性,可能适用于某些特定的应用场景。
Temperature Sampling
Temperature Sampling 是一种控制生成文本的随机性和创造性的参数。它作用于模型输出的概率分布,影响模型选择下一个词语的方式。 简单来说,它控制了模型“胆量”的大小,决定了模型是倾向于选择最可能的(保守的)词语,还是偶尔选择不太可能的(冒险的)词语。
算法公式
\[\Large P(k) = \frac{\mathcal{e}^{\frac{p_k}{T}}}{\sum_{i} \mathcal{e}^{\frac{p_i}{T}}}\]
算法图解
如下图所示,描述了上述算法:
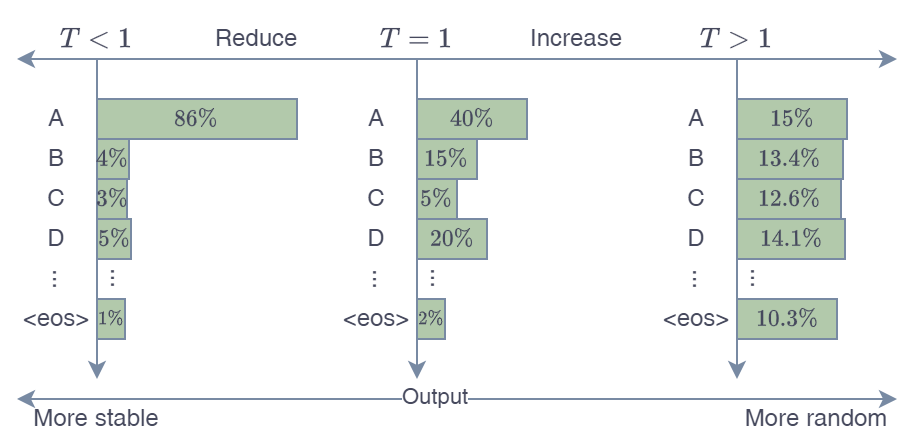
T = 1 (原始): Temperature 为 1 时,概率分布保持不变,模型按照原始概率进行采样。 这意味着模型会更频繁地选择最可能的词语。
T < 1 (降低): Temperature 小于 1 时,概率分布会更加陡峭,概率高的词语变得更高,概率低的词语变得更低。 这会使模型更倾向于选择最可能的词语,生成更保守、更可预测、更流畅、更少新意的文本。 极端情况下,如果 T 趋近于 0,模型会几乎总是选择概率最高的词语,生成非常单调和重复的文本 (类似于贪婪搜索)。
T > 1 (升高): Temperature 大于 1 时,概率分布会更加平滑,概率高的词语相对降低,概率低的词语相对升高。 这会使模型更具创造性,更有可能选择不太可能的词语,生成更出人意料、更随机、更有创意的文本。但也可能导致语法错误或语义不连贯。
基于信息熵
Typical Sampling
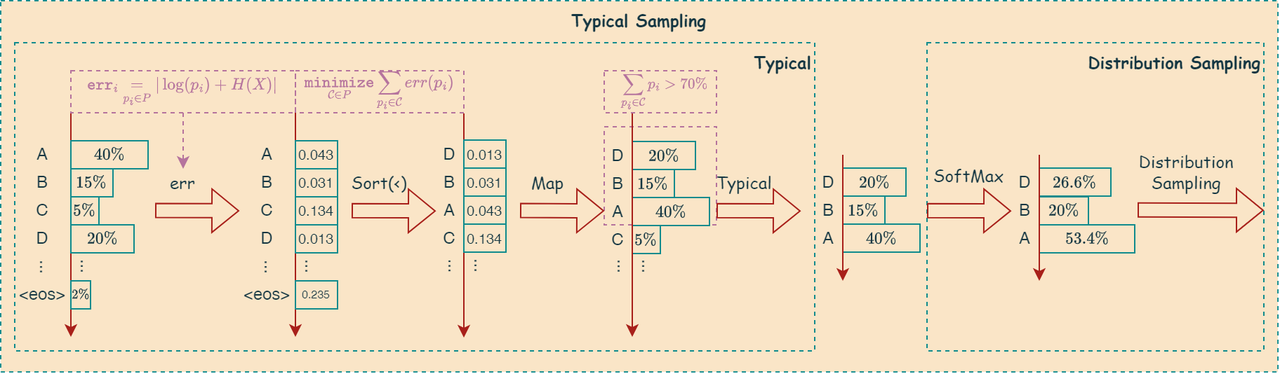
Typical Sampling 或称作 Locally Typical Sampling是一种旨在生成更符合人类语言模式的文本采样策略。它的核心思想是:根据词汇的概率分布,识别并采样那些“典型”或“常见”的词,而避免选择那些概率极高或极低的“不典型”的词。这种方法试图捕捉人类语言的统计规律,即在交流中,我们倾向于使用出现频率适中的词汇,而不是过于生僻或过于常见的词汇。
数学公式表示如下:
\[\Large \underset{\mathcal{C}\in P}{\mathtt{minimize}} \sum_{y\in\mathcal{C}'(y_{<t})}|H(Y_t|Y_{<t}=y_{<t})+\log \Big(p(y|y_{<t})\Big)|, \quad \sum_{y\in\mathcal{C}}p(y|y_{<t})\ge \tau\]
算法图解
如下图所示,描述了上述算法:
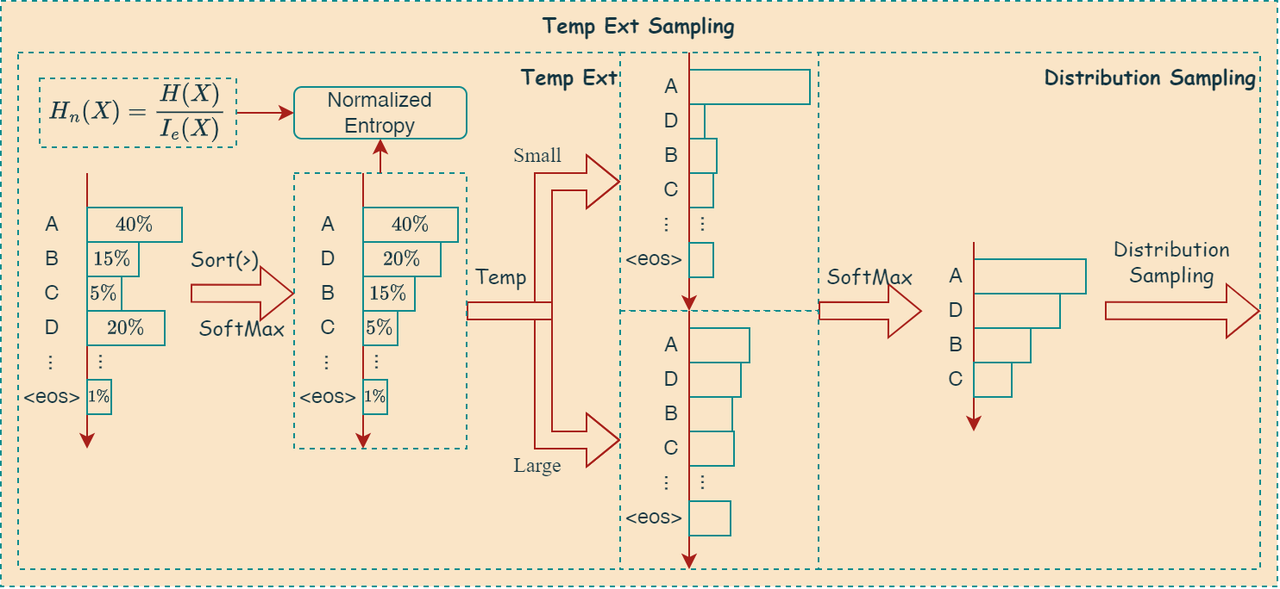
Temperature Extra Sampling
- 高熵 (多样性高) 时使用高温度: 当候选 token 的概率分布熵较高时,说明 token 的概率分布比较均匀,多样性较高,此时使用较高的温度,使得概率分布更加平滑,增加采样多样性。
- 低熵 (多样性低) 时使用低温度: 当候选 token 的概率分布熵较低时,说明 token 的概率分布比较集中,某个 token 的概率明显高于其他 token,此时使用较低的温度,使得概率分布更加尖锐,倾向于选择概率最高的 token,减少采样多样性。
算法步骤
代码的工作流程可以概括为:
- 获取采样器上下文和参数。
- 计算最大可能熵和当前概率分布的熵。
- 归一化熵,并使用幂函数将其映射到动态温度范围。
- 应用动态温度缩放 logits。
- 重新计算 softmax 概率。
算法图解
如下图所示,描述了上述算法:
基于困惑度
Microstat Sampling
算法流程如下:

Microstat V2 Sampling
mirostat v2 算法相对于原始 mirostat 算法更加简洁和直接。它通过直接截断 surprise 值 \(I(x_i)\) 大于 \(\mu\) 的 token 来控制生成文本的 surprise 值。算法的核心仍然是根据观察到的 surprise 值与目标 surprise 值的误差来更新自适应参数 \(\mu\) 。这种方法避免了原始 mirostat 算法中复杂的 k 值计算,可能更易于理解和实现。mirostat v2 同样致力于在生成高质量文本的同时,避免生成重复或过于平淡的文本。
找到第一个 surprise 值大于\(\mu\)的 token。
基于语法规则
Grammar Sampling
Grammar Sampling 指的是在文本生成过程中,利用语法规则来约束或引导采样过程,从而确保生成的文本在语法结构上是正确的、符合特定规范的。这种方法可以应用于各种文本生成任务,例如代码生成、数据解析、自然语言生成等。
核心思想
Grammar Sampling 的核心思想是将语法规则编码成一种形式,然后在采样过程中利用这种形式来限制或指导模型的输出。通常,语法规则可以用以下几种形式表示:
- 上下文无关文法 (Context-Free Grammar, CFG): CFG 是一种常用的语法表示方法,它使用一组产生式规则来定义语言的结构。例如,一个简单的算术表达式 CFG 可以定义如下:
1 | E -> E + T | T |
- 其中,E 表示表达式,T 表示项,F 表示因子,num 表示数字。
- 正则表达式 (Regular Expression): 正则表达式可以用于描述字符串的模式,例如,[a-z]+@[a-z]+.[a-z]+ 可以匹配电子邮件地址。
- 类型系统 (Type System): 在程序代码生成中,类型系统可以用于约束生成的代码的类型正确性。
实现方法
Grammar sampling 的实现方法可以分为以下几类:
受限采样 (Constrained Sampling):
- 前向采样: 在生成每个词或符号时,根据语法规则,只允许采样符合当前语法结构的词或符号。例如,在 CFG 中,如果当前需要生成一个表达式 E,则只能采样符合 E 的产生式规则的符号。
- 后向采样: 首先随机生成一个完整的句子或序列,然后根据语法规则对其进行修改或过滤,使其符合语法结构。
引导采样 (Guided Sampling):
- 修改概率分布: 在采样过程中,根据语法规则修改模型输出的概率分布,增加符合语法结构的词或符号的概率,降低不符合语法结构的词或符号的概率。
- 使用语法嵌入 (Grammar Embedding): 将语法规则编码成向量表示,然后将其与语言模型的输出结合,引导模型生成符合语法结构的文本。
解析与生成结合 (Parsing and Generation):
- 先解析后生成: 首先利用语法解析器解析部分生成的文本,然后根据解析结果指导后续的生成过程。
- 交替解析与生成: 在生成过程中,交替进行解析和生成,确保生成的文本始终符合语法规则。
优点
- 语法正确性: Grammar sampling 可以保证生成的文本在语法结构上是正确的,避免生成语法错误或不符合规范的文本。
- 可控性: 通过调整语法规则,可以控制生成文本的结构和风格。
- 适用性: Grammar sampling 可以应用于各种需要语法约束的文本生成任务。
缺点
- 复杂度: Grammar sampling 的实现通常比较复杂,需要对语法规则进行编码和处理。
- 效率: 由于需要进行语法检查或约束,grammar sampling 可能会降低文本生成的效率。
- 灵活性: 过于严格的语法约束可能会限制模型的创造力,导致生成文本过于单一。
应用场景
- 代码生成: 根据自然语言描述生成代码,需要保证生成的代码在语法和语义上都是正确的。
- 数据解析: 从非结构化文本中提取结构化数据,需要根据预定义的语法规则解析文本。
- 受控自然语言生成: 生成特定风格或结构的文本,例如生成法律文件、技术文档等。
- 对话系统: 生成符合特定对话流程或语法的对话回复。
基于惩罚原则
DRY Sampling
DRY(不要重复自己)采样器是一种动态的 N 元语法重复惩罚机制,防止语言模型生成重复的文本序列,它会对那些会扩展已经出现在上下文中的序列的标记给予负面评分。 通过结合重启序列和Z-算法,高效地计算并应用重复惩罚,从而有效地防止语言模型生成重复的文本序列。该函数的核心思想是惩罚那些会导致重复序列的 token,同时避免惩罚那些构成重启序列的 token,从而在保持文本多样性的同时,允许模型生成合理的重复内容。
DRY: A modern repetition penalty that reliably prevents looping by p-e-w · Pull Request #5677 · ooba
核心思路和算法
参数检查与提前退出
- 函数首先检查几个参数:dry_multiplier,dry_base 和 dry_penalty_last_n。如果这些参数指示不需要惩罚(例如,乘数为 0 或基数小于 1),函数将直接返回。这可以提高效率,避免不必要的计算。
- 同时,计算effective_dry_penalty_last_n,这个值决定了要检查的上下文窗口大小,用于查找重复序列。
- 如果last_n_repeat (实际要检查的token数量) 小于等于dry_allowed_length (允许的重复长度),也直接返回,因为没有超过允许的重复长度。
查找重启序列(Restart Sequences)
- 重启序列是一组特殊的 token 序列,用于标记文本的重新开始或分段。例如,在一个对话场景中,每个新的发言可以被视为一个重启序列。
- 代码通过 ctx->dry_processed_breakers 存储重启序列的信息,它是一个 std::multimap,将重启序列的起始 token 映射到其后续 token 序列。
- 这段代码反向遍历最近生成的 token 序列 (ctx->last_tokens),查找是否存在任何重启序列。如果找到一个重启序列,它会限制后续重复惩罚的范围,避免惩罚跨越重启序列的重复。 这确保了惩罚只应用于在同一个 "段落" 或 "主题" 内的重复,而不是跨越不同段落或主题的重复。
- rep_limit 变量记录了从当前位置到最近的重启序列的距离。
使用 Z-算法计算重复计数
- Z-算法是一种高效的字符串匹配算法,用于计算一个字符串的每个后缀与字符串本身的前缀匹配的长度。
- 在这里,Z-算法被用于计算最近生成的 token 序列中每个 token 的重复计数。ctx->dry_repeat_count 数组存储了每个 token 的重复计数,表示该 token 在其之前出现了多少次。
- 这一步的核心是找到重复出现的子序列,并记录其长度。
计算最大重复长度
- 遍历 dry_repeat_count 数组和 last_tokens,计算每个 token 的最大重复长度。最大重复长度是指如果生成该 token,将会形成多长的重复序列。
- ctx->dry_max_token_repeat map 存储了每个 token 的最大重复长度。
应用 Logit 惩罚
- 根据每个 token 的最大重复长度,应用 logit 惩罚。惩罚的强度由 dry_multiplier 和 dry_base 参数控制。
- dry_base 参数控制惩罚的基数,dry_multiplier 参数控制惩罚的幅度。
- 如果一个 token 的最大重复长度超过了允许的重复长度 (dry_allowed_length),则对其应用惩罚。惩罚值与重复长度呈指数关系,重复长度越长,惩罚越大。
- 需要注意的是,单 token 的重启序列不会被惩罚。这是因为单 token 重启序列通常表示重要的语义转折,不应该被抑制。
更新排序标志
- 由于应用了 logit 惩罚,候选 token 的概率分布发生了变化,因此需要将 cur_p->sorted 设置为 false,指示 cur_p 中的 token 需要重新排序。
Penalties Sampling
penalties采样算法实现了一个灵活的 token 惩罚机制,可以用于控制生成文本的重复性和特殊 token 的行为。它通过统计最近生成 token 的频率,并对当前候选 token 的 logits 应用惩罚来实现这一目标。惩罚类型包括重复惩罚、频率惩罚和存在惩罚,可以分别调整以达到不同的效果。此外,代码还对 EOS token 和换行符 token 进行了特殊处理,以满足特定的生成需求。
EOS token 如果 ctx->ignore_eos 为真,则对 EOS(句子结束)token 的 logits 设置为负无穷大 (-INFINITY),以避免生成 EOS token。
换行符 token 如果 ctx->penalize_nl 为假,则需要特殊处理换行符 token。
惩罚参数检查 如果 penalty_last_n 为 0或者所有惩罚系数都为默认值(不进行惩罚),则直接返回,不进行任何惩罚操作。
重复惩罚
1 | if (cur_p->data[i].logit <= 0) { |
- 频率惩罚
1 | -float(count) * ctx->penalty_freq |
- 存在惩罚
1 | -float(count > 0) * ctx->penalty_present |
其它
Infill Sampling
Infill采样的核心思路是通过控制 EOG token 的概率、合并共享前缀 token、以及进行概率阈值过滤和归一化,来生成连贯、准确且完整的代码片段。它旨在平衡代码生成和代码结束之间的关系,同时提高生成代码的质量和效率。
平衡代码生成与代码结束
- 识别 EOG Token:算法首先区分代码结束(EOG) token 和普通文本 token。
- EOG 概率控制:通过计算 EOG token 和文本 token 的概率总和,并比较它们之间的比例。如果 EOG token 的概率过高,则认为模型倾向于过早结束代码生成。此时,算法会抑制文本 token,只保留 EOG token 进行采样,从而确保代码生成的完整性。
- EOT Token兜底:如果经过过滤后没有保留任何非EOG Token,说明模型无法生成有效代码,此时会强制生成一个EOT(文本结束)Token,结束生成流程。
增强代码连贯性与准确性
- 合并共享前缀 Token:算法会识别并合并具有相同前缀的 token。例如,如果存在 token "print" 和 "printf",算法会将它们合并,将 "printf" 的概率累加到 "print" 上(假设"print"的概率更高),从而避免生成重复或冗余的代码,并提高代码的连贯性。
- 两次概率阈值过滤:算法应用两次概率阈值过滤,第一次过滤是为了移除概率过低的token,保留相对重要的候选token,第二次过滤的阈值与非EOG Token数量相关,目的是进一步筛选token,保留概率更高的token。这样可以过滤掉不太可能的 token,提高生成代码的准确性,避免生成无意义或不相关的代码。
概率分布调整与归一化
- Softmax 转换:首先将 logits 转换为概率分布,以便进行后续的概率操作。
- 概率归一化:在过滤和合并 token 后,算法会重新归一化概率分布,确保所有保留 token 的概率总和为 1,以便进行正确的采样。
Logit Bias Sampling
logit bias采样的作用是在采样的过程中,对特定 token 的 logits(对数概率)添加一个偏置值,从而影响 token 被采样的概率。 \[logit = logit + bias\]