多模态模型分析-面壁MiniCPMV
概述
MiniCPM 是面壁与清华大学自然语言处理实验室共同开源的系列端侧大语言模型,主体语言模型 MiniCPM-1B 仅有 12亿(1.2B)的非词嵌入参数量。
模型框架介绍
如下图所示,是MiniCPMV模型的多模态推理流程图。如果有图片输入,会在文本字段中添加 (<image>./</image>)占位符号,表示需要基于该图片特征进行内容的生成,当然也可以支持多个图片的输入,简单示例如下:
- 单张图片
1 | (<image>./</image>)What is this picture? |
- 多张图片
1 | (<image>./</image>)(<image>./</image>)What is those pictures? |
那么从图片的像素特征空间转到语言模型特征空间后,其等效的文本token长度固定为64,多张图片的token长度则对应为64的倍数。

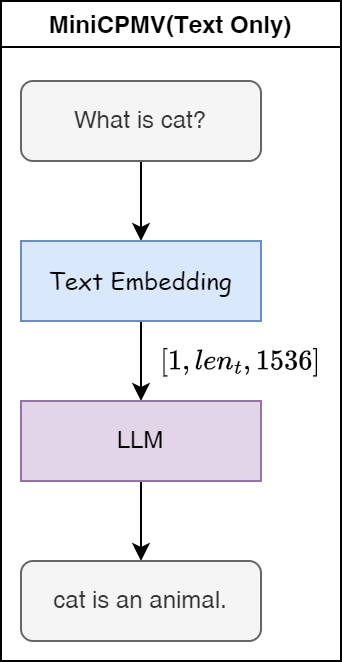
如果只有文本输入,则流程图如下:
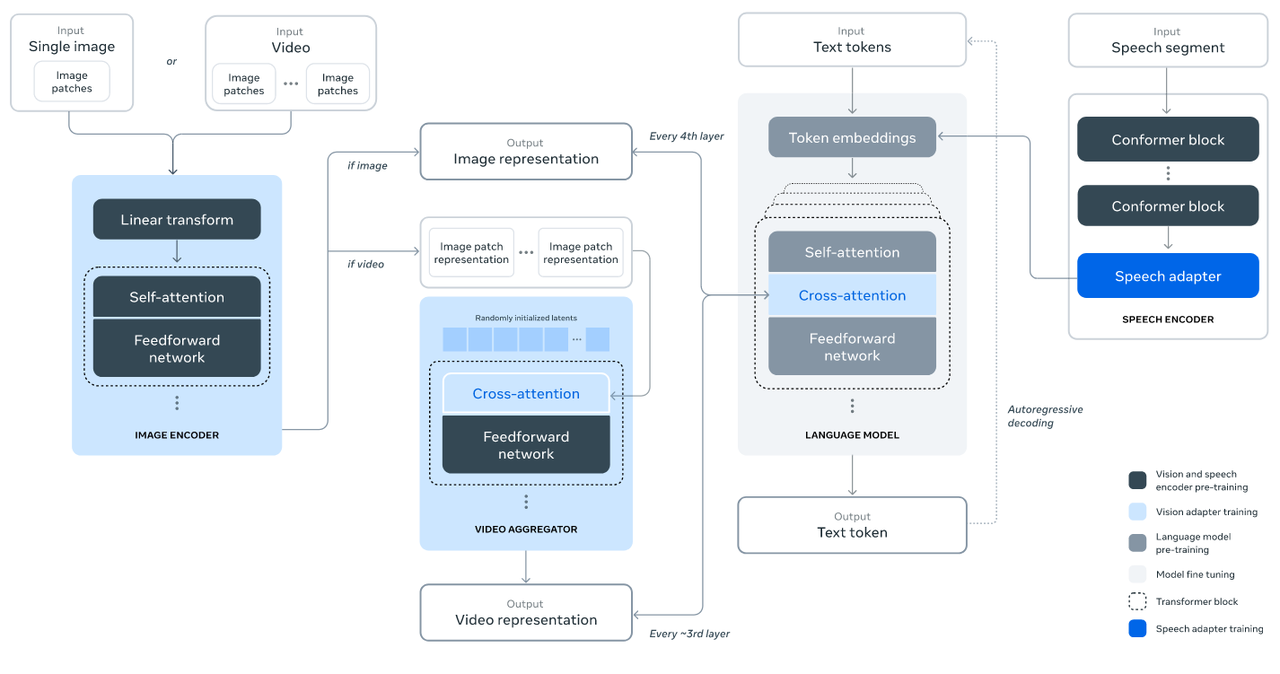
如下图所示,是Llama3.2的整体结构框图,支持图片、视频和语音等多个模态的输入,MiniCPMV一定程度上借鉴了Llama3.2的模型框架,并为了适应端侧部署进行了相关改进。
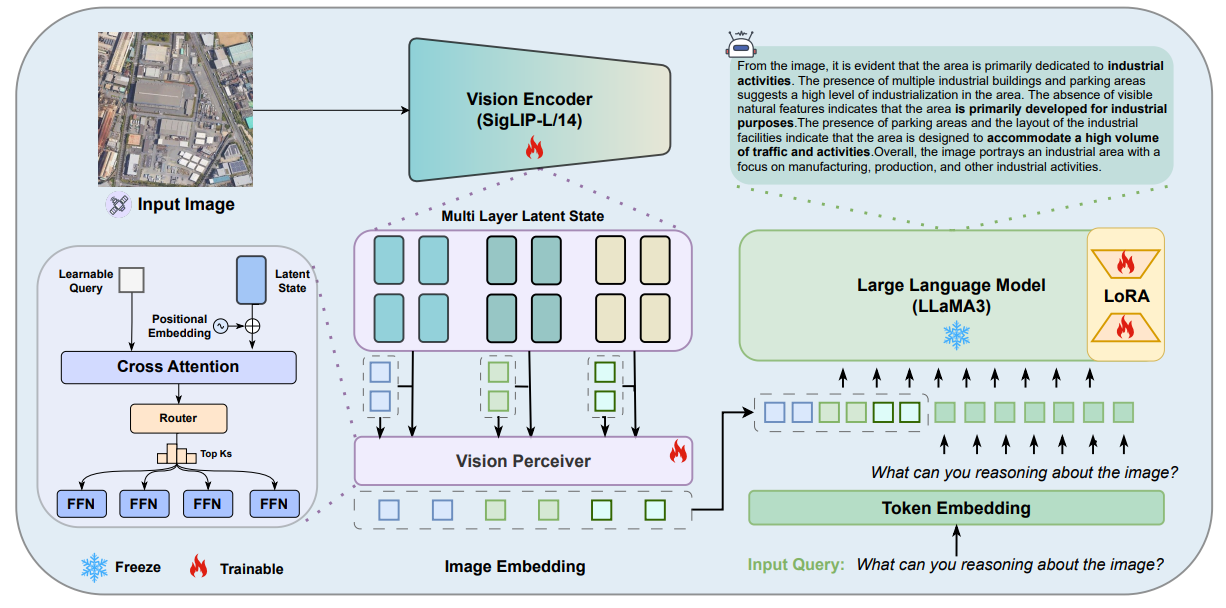
MiniCPMV模型框架更接近下图所示的模型框架,使用 SigLip 模型实现对图片的编码,其编码后的特征空间等效为某些文本描述的特征空间,最后通过交叉注意力机制对编码器输出的特征空间进行 Query,获取与语言模型文本模态输入对齐的特征空间。
Vision Preprocess
图片输入尺寸默认为 448x448 ,按照patch 14x14 对原图片进行切片,一共切1024个图像块,并平铺图像块,得到 \([3,14,14336]\) 大小的像素矩阵。

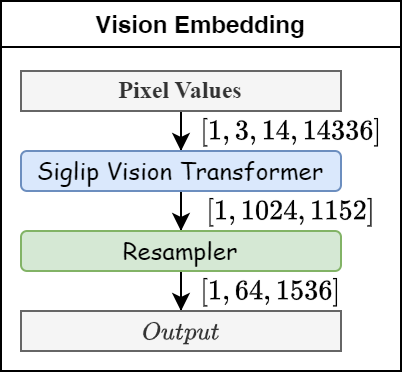
Vision Embedding
视觉嵌入模块将预处理后的像素矩阵转换为嵌入维度为1536,大小为64的嵌入矩阵,其主要包含 Siglip Vision Transformer 和 Resampler 两个模块。
- Siglip Vision Transformer(Image encoder):负责从像素空间提取与文本描述等效的特征空间;
- Resampler(Image adapter):负责将视觉模态的嵌入序列转换为文本模态的嵌入序列,或者可以理解为构建了视觉特征与语言模型之间的适配器。
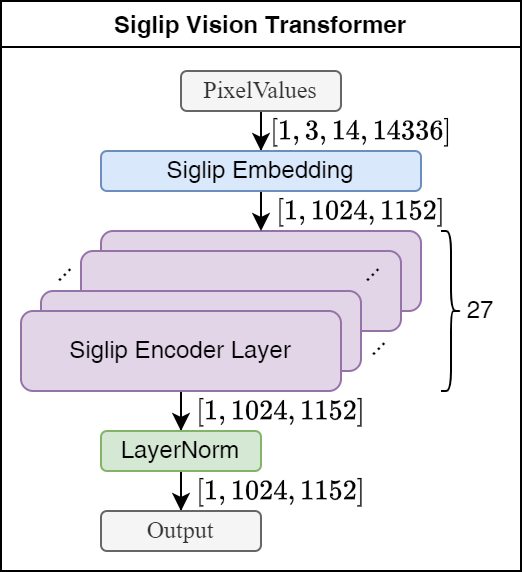
Siglip Vision Transformer Module(CLIP)
该模块由27层Ecoder模块组成,进行图片特征的提取,只获取最后一层图片的特征。
ViT
如下图所示,Siglip模块整体结构类似于ViT。 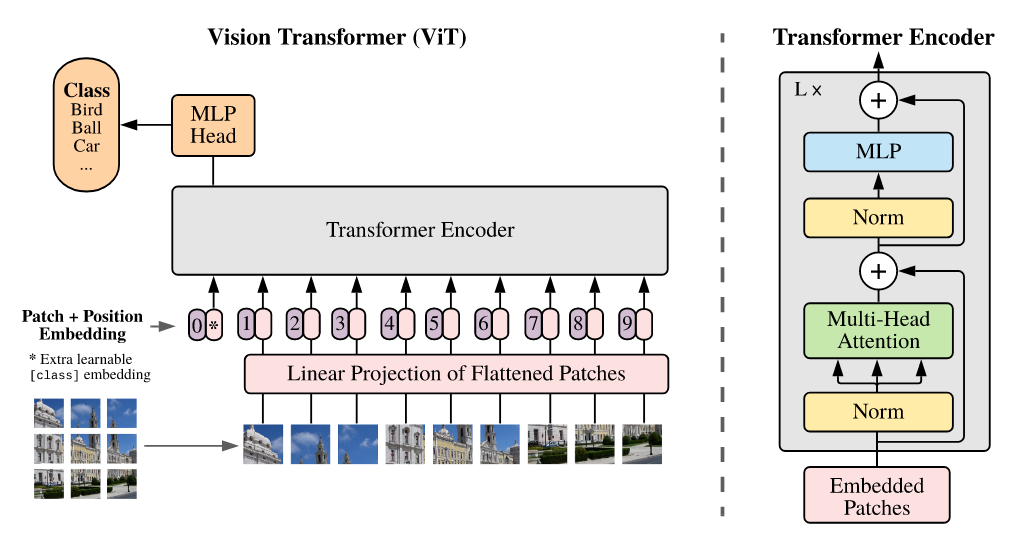
CLIP
模型训练采取的是 Contrastive Language–Image Pre-training(CLIP) 模型的方式,基于对比学习,通过同时学习图像和文本的表示,使得相似的图像和文本在特征空间中的表示更加接近。具体来说,CLIP模型包含两个主要部分:Text Encoder(文本编码器)和 Image Encoder(图像编码器)。
- 文本编码器:将输入的文本转换为一系列向量,这些向量捕捉文本的语义信息。
- 图像编码器:将输入的图像转换为一系列向量,这些向量捕捉图像的视觉特征。
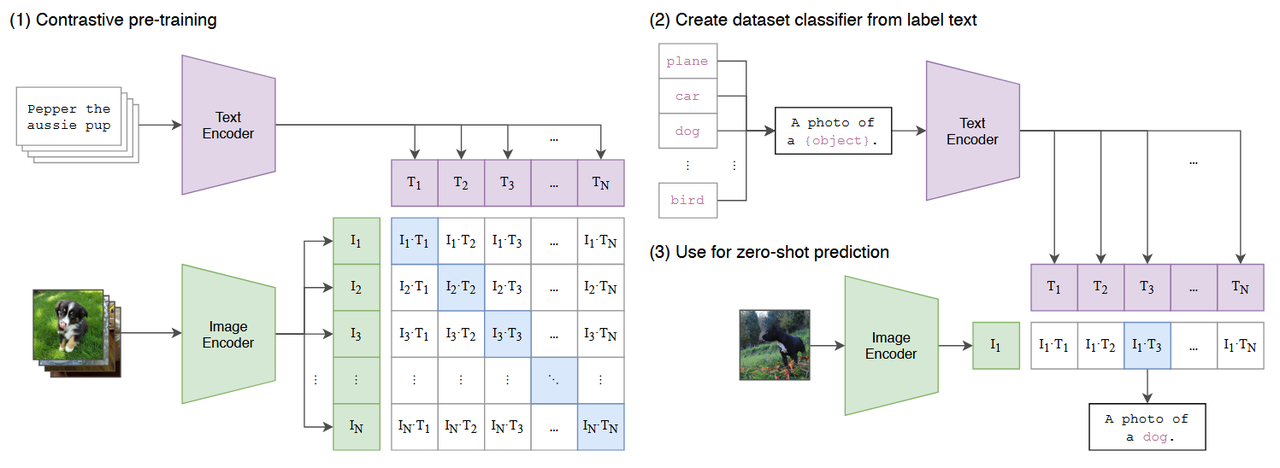
在训练过程中,CLIP模型通过对比学习来优化文本和图像编码器,使得匹配的文本和图像对在特征空间中的距离更近,而不匹配的文本和图像对距离更远。这种学习方式使得CLIP模型能够有效地理解图像和文本之间的关系。
- CLIP模型具有以下性质:
- 多模态理解能力:能够同时理解图像和文本信息,实现跨模态的检索与匹配。
- 强大的泛化能力:由于采用了自然语言监督,CLIP模型具有较好的泛化性能,可以处理未见过的类别和场景。
- 灵活性:CLIP模型可以轻松地适应不同的任务和数据集,无需进行大量的微调。
- CLIP模型的应用场景主要包括:
- 文本到图像的生成:根据用户输入的文本提示生成相应的图像。CLIP模型将文本描述转换为特征向量,指导图像生成模型(如U-Net)生成与文本描述相符的图像。
- 图像检索与分类:利用CLIP模型的多模态理解能力,实现基于文本的图像检索和分类任务。例如,在电商平台上,用户可以通过输入文本描述来搜索相关商品图像。
Siglip
CLIP中的infoNCE损失是一种对比性损失,在SigLIP这个工作中,作者提出采用非对比性的sigmoid损失,能够更高效地进行图文预训练。
Siglip Embedding
如下图所示,原始像素组成的矩阵通过卷积和位置编码后生成视觉编码器所需的嵌入向量。其中,卷积的输出通道的大小与编码器所需的嵌入向量维度一致,卷积内核和步长与像素patch的大小保持一致。
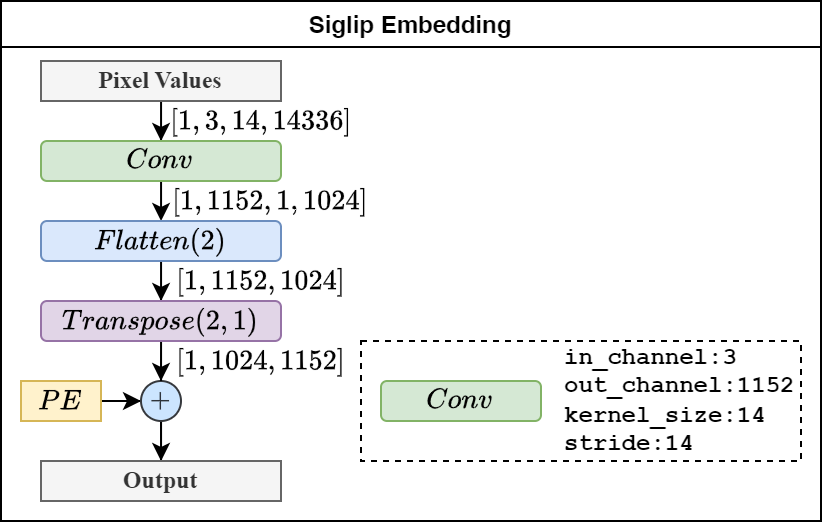
Siglip Encoder Layer
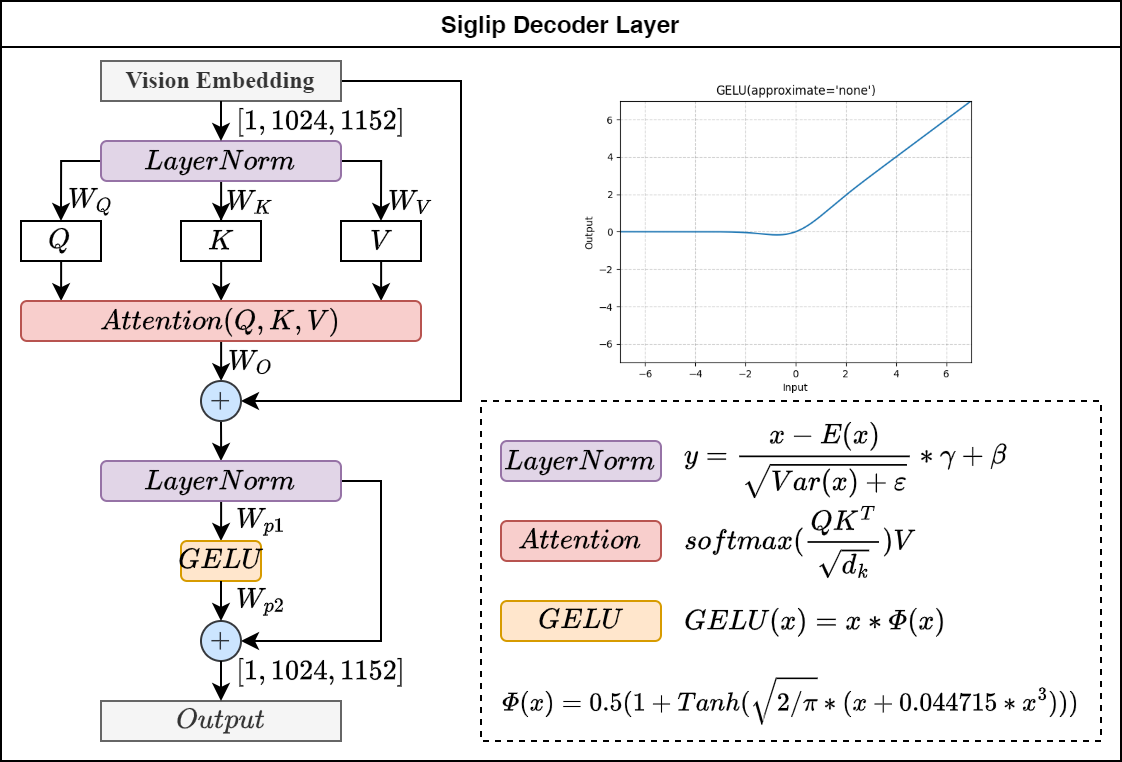
视觉Encoder器的网络结构与ViT的结构类似,如下图所示:
Resampler
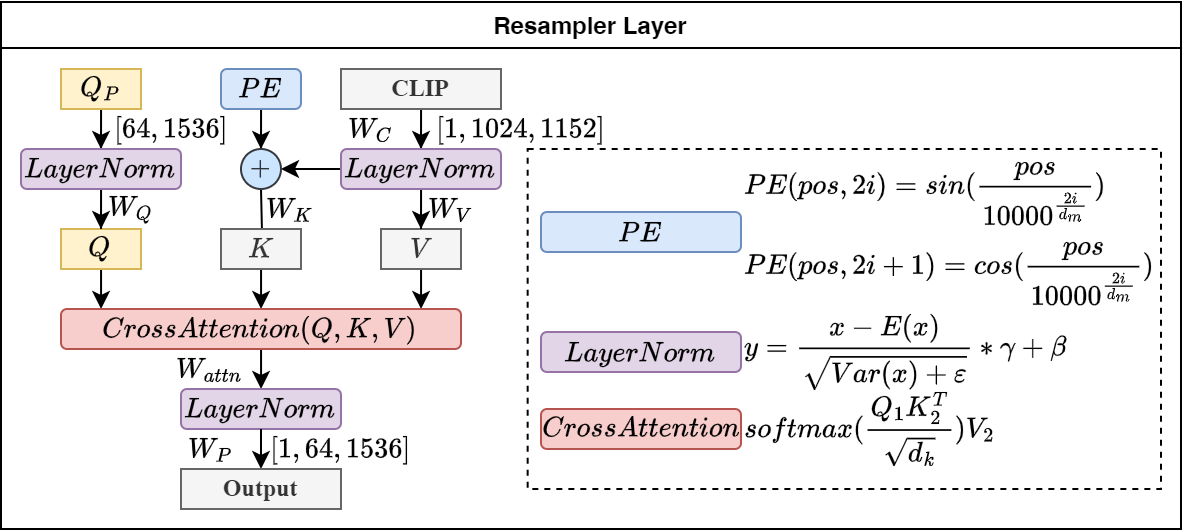
Resampler模块采用 Cross-Attention 机制,及表示Transformer架构中混合两种不同模态的嵌入序列的注意机制。
- 两个序列必须具有相同的维度;
- 两个序列可以是不同的模态(如:文本、声音、图像);
- 一个序列作为输入的Q,定义了输出的序列长度,另一个序列提供输入的 \(K\) 和 \(V\); 公式表示如下: \[CrossAttention = Softmax(\frac{Linear(W_Q,S_2)*Linear(W_K,S_1)^T}{\sqrt{d_k}})Linear(W_V,S_1)\]
如下图所示, \(Q_{P}\)表示学习的参数,其定义的输出序列的长度也为64, \(CLIP\)表示视觉模态序列,通过交叉注意力机制,最终将视觉模态序列转为文本模态序列。
MiniCPM LLM
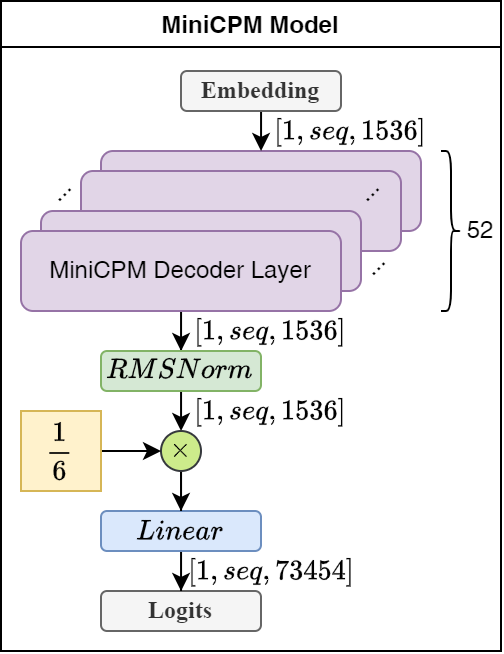
下图所示,是LLM的总体架构,一共52层Decoder层,整体结构与Llama3类似。
MiniCPM Decoder Layer
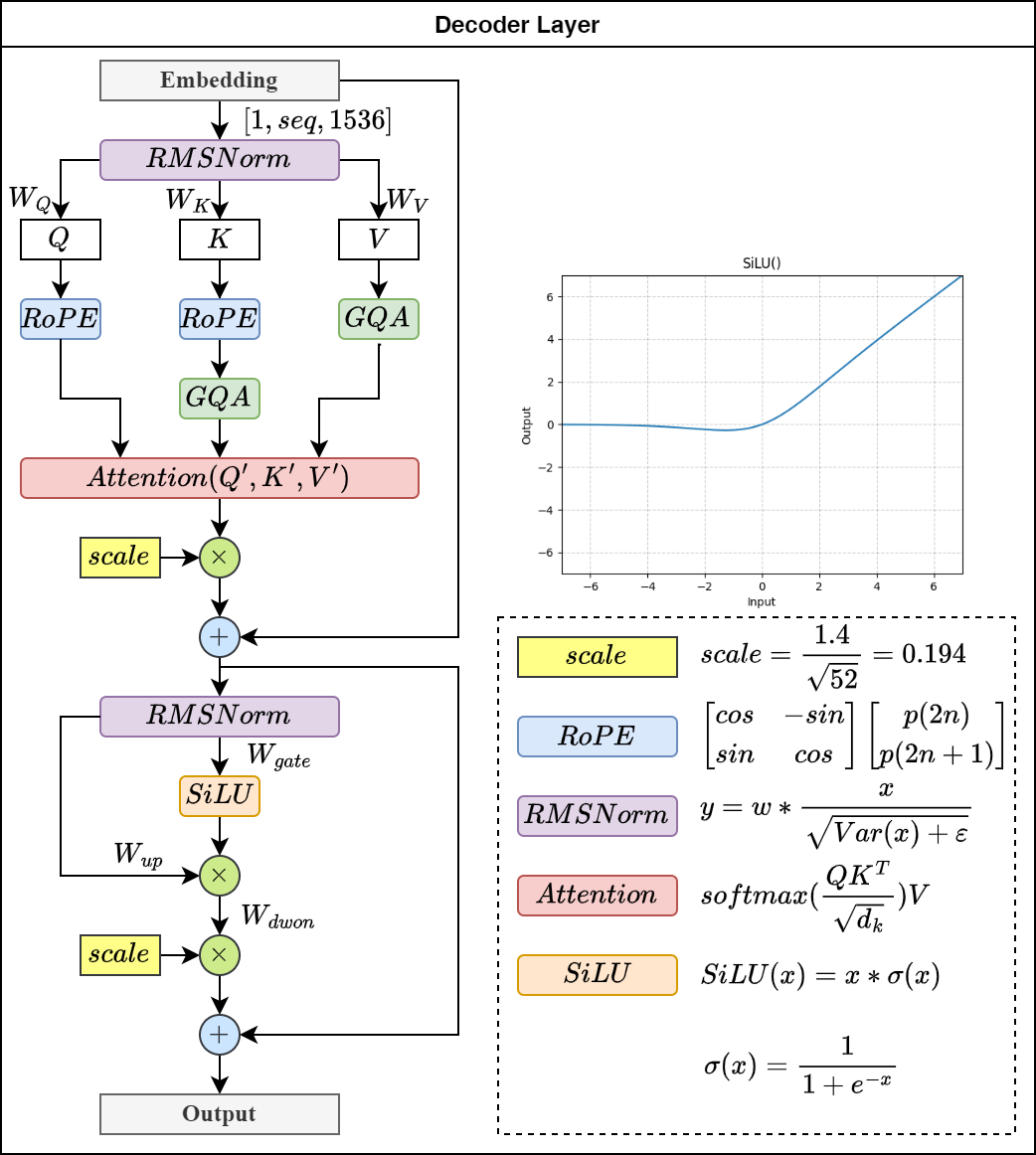
RMSNorm
设计选择主要基于以下考虑:
- 简化: 没有可学习的参数,简化了模型的训练和优化。
- 稳定性: 避免了均值中心化,提高了数值稳定性。
- 效率: 计算量略小于标准 LayerNorm。
1 | def rms_layernorm(hidden: torch.Tensor, weight: torch.Tensor, eps: float): |
Rotary Position Embedding
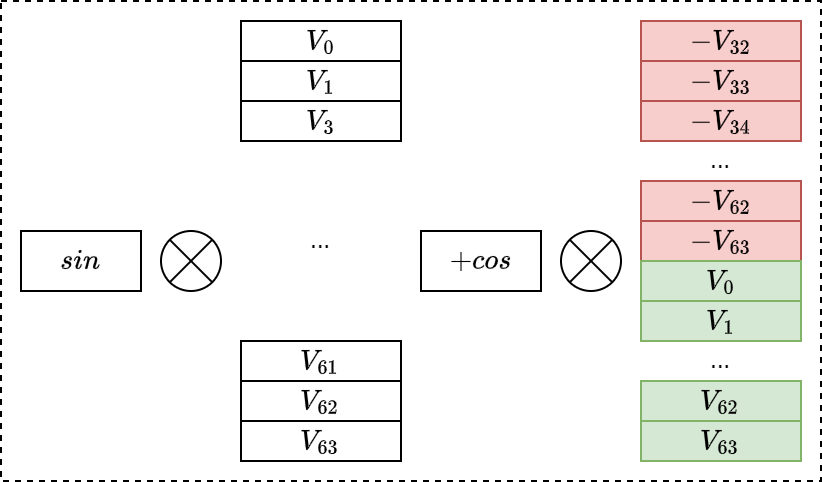
等效如下公式: \[\begin{bmatrix} cos & -sin \\ sin & cos \end{bmatrix}\begin{bmatrix}p(2i) \\ p(2i+1)\end{bmatrix}\]
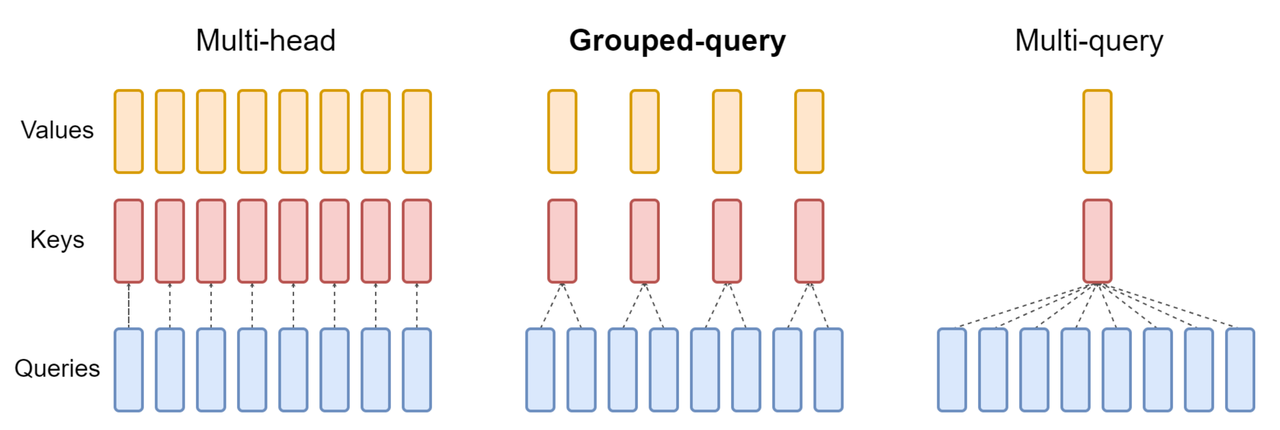
Group Query Attention
Group Query Attention(GQA)示意图如下:
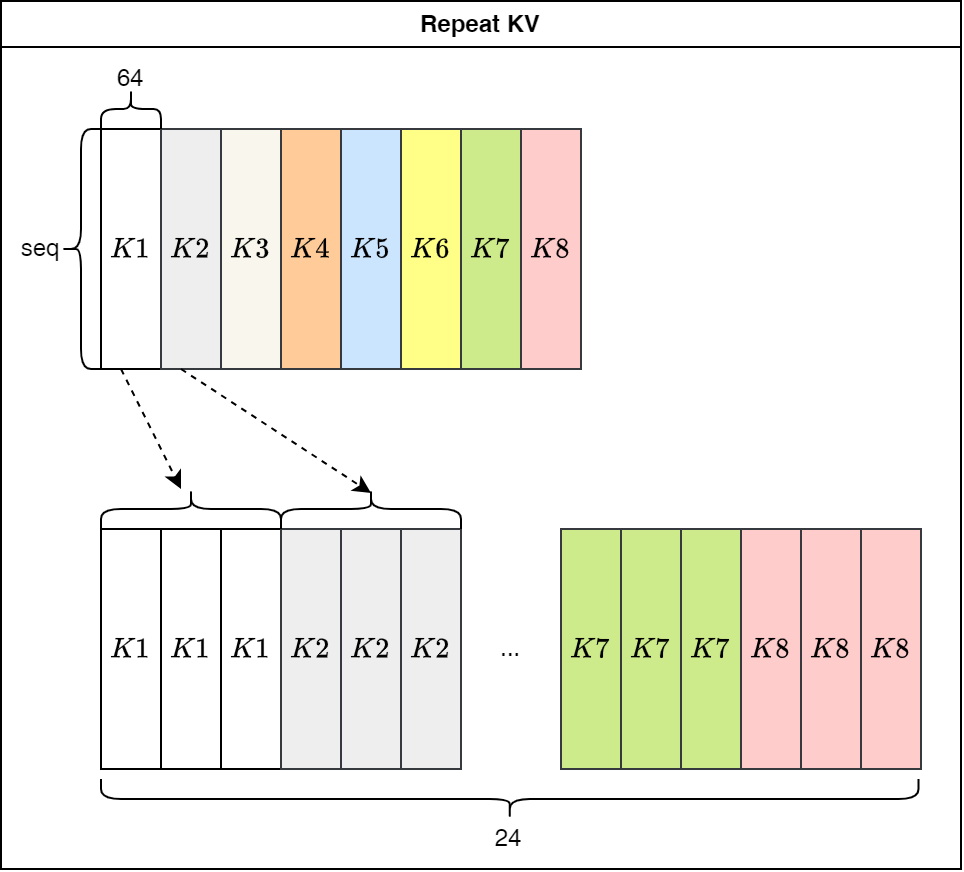
代码中的repeat KV模块实际上就是将共享的KV值重复展开,与Q的维度对齐。
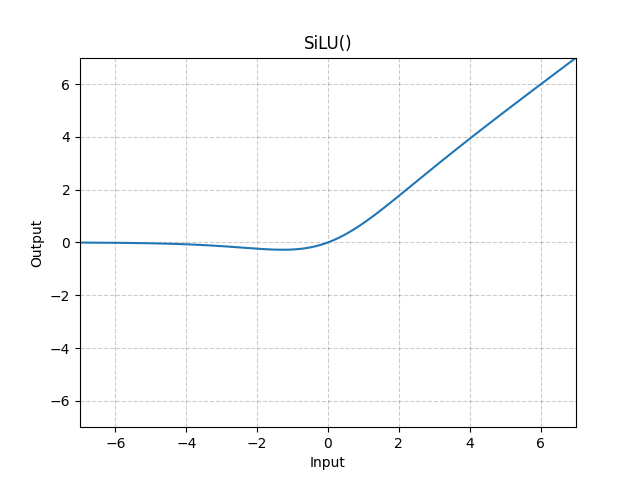
SiLU
\[silu(x)=x*\sigma(x)\] 其中, \(\sigma(x)\)表示逻辑sigmoid。