SenseVoiceSmall-语音识别模型分析
概述
目前板端部署的语音模型是通义千问的SenseVoice Small模型,具有如下优点:
- 多语言识别: 采用超过40万小时数据训练,支持超过50种语言,识别效果上优于Whisper模型。
- 富文本识别:
- 具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。
- 支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。
- 高效推理: SenseVoice-Small模型采用非自回归端到端框架,推理延迟极低,10s音频推理仅耗时70ms,15倍优于Whisper-Large。
- 微调定制: 具备便捷的微调脚本与策略,方便用户根据业务场景修复长尾样本问题。
- 服务部署: 具有完整的服务部署链路,支持多并发请求,支持客户端语言有,python、c++、html、java与c#等。
在语音特征前添加四个嵌入作为输入传递给编码器:
- LID:用于预测音频语种标签。
- SER:用于预测音频情感标签。
- AED:用于预测音频包含的事件标签。
- ITN:用于指定识别输出文本是否进行逆文本正则化。
模型架构
模型总体架构如下图所示,主要由 SAN-M Encoder 和 CTC 模块组成。
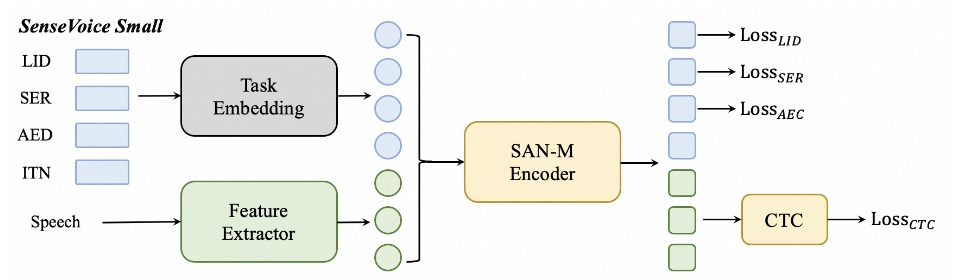
- 前处理
给定输入波形,首先计算80维对数梅尔滤波器组(FBank),然后将连续帧堆叠起来,并对其进行6倍下采样(LFR)。
SAN-M Encoder
下图是SAN-M Encoder模块内部的结构图,其由多层SAN-M层组成,用于捕获输入序列的特征。
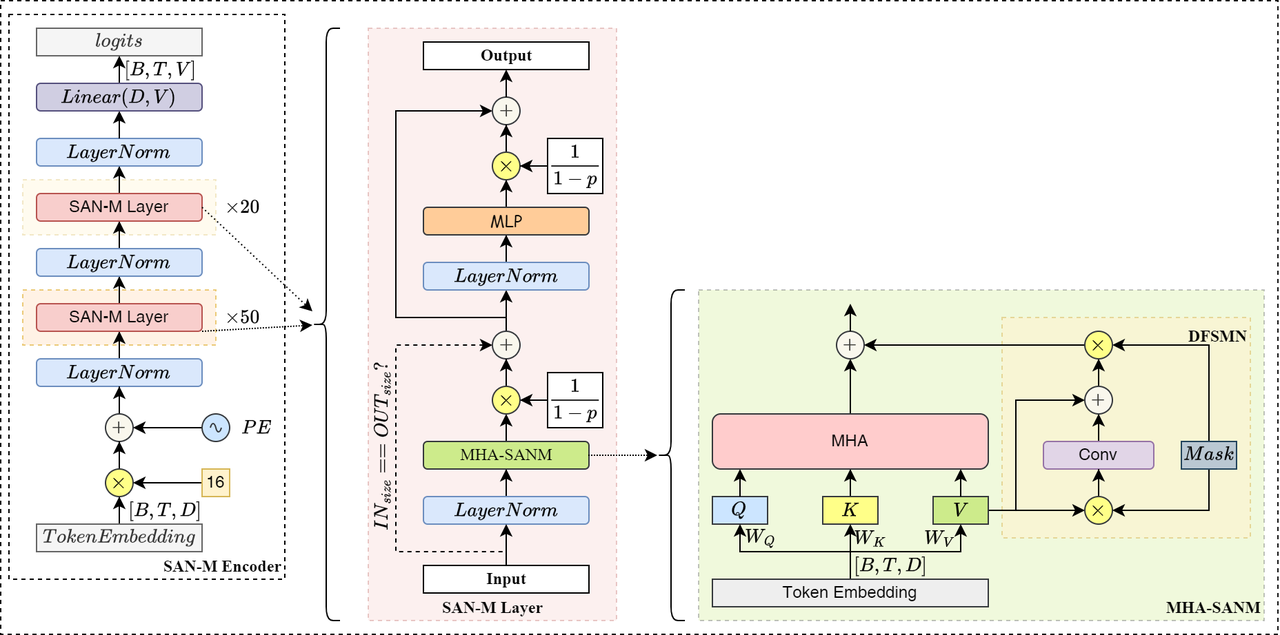
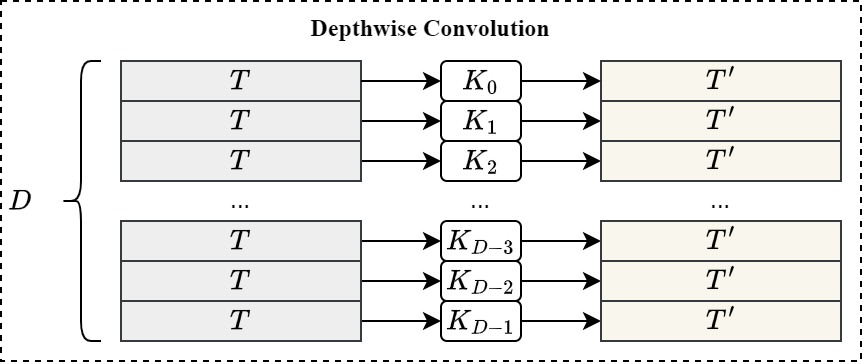
其中,DFSMN模块主要使用Depthwise 1D Convolution实现类似FIR滤波器结构,展开后结构如下:
SAN-M模块
如下图所示,整体是在多头注意力机制内的 Value 上添加了DFSMN滤波器,滤波器的值存储在内存块中。最后将内存块中的内容添加到多头注意力机制的输出中。
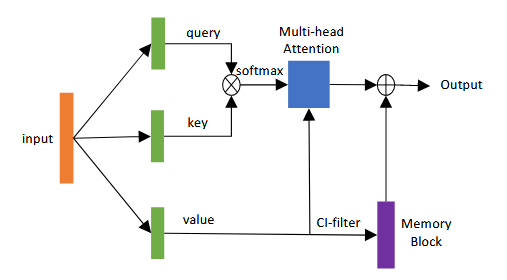
可以表示为: \[Y = MultiHead(Q,K,V) + M(V)\] 其中, \(Y\)表示SAN-M模块的输出。
编码阶段(Encoder)
如下图a所示,自注意力机制在不同编码器层学习到的依赖上下文的系数具有明显的对角成分,随着层数的增加,这种对角成分变得更加弥散和宽泛。这表明学习到的特征主要是局部依赖的,尽管自注意力有能力对整个序列的长期依赖关系进行建模。

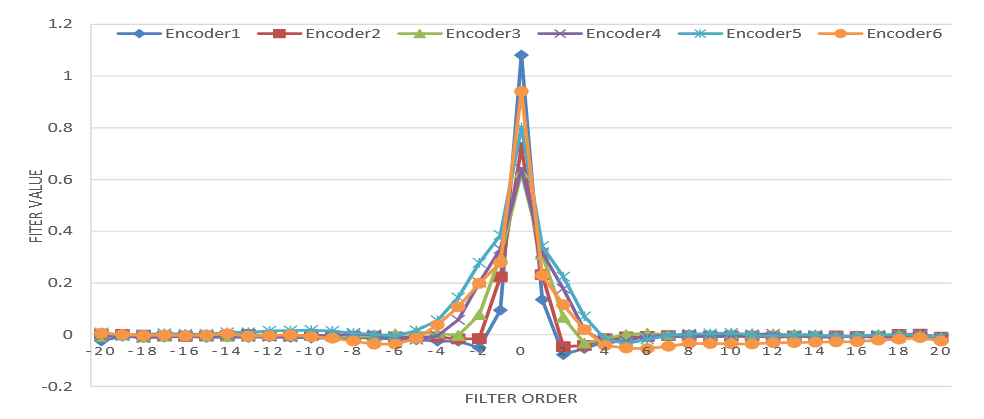
如上图b所示,DFSMN记忆块在同样的编码器层学习到的不依赖上下文的系数呈现塔状的形状,随着层数的增加,这种塔状形状的宽度也在增加。
解码阶段(Decoder)
从下图 (a) 和 (b) 中可以看出,自注意力在解码器层所学习到的依赖关系比 DFSMN 记忆块所学习到的长期依赖关系更长。
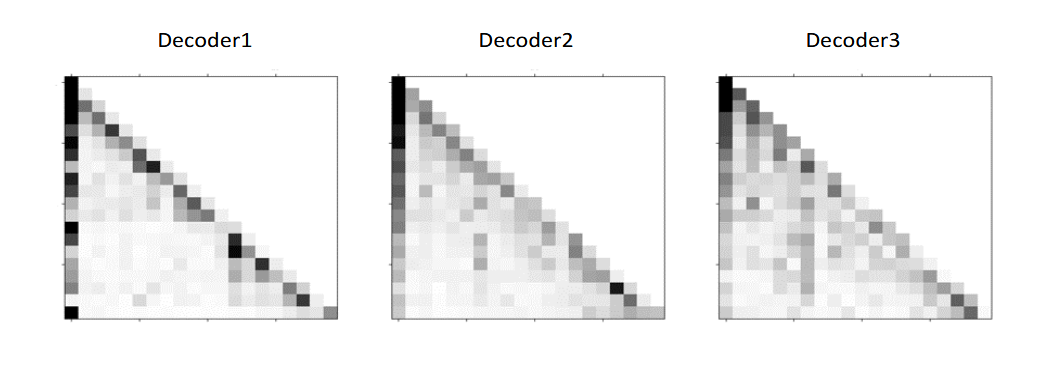
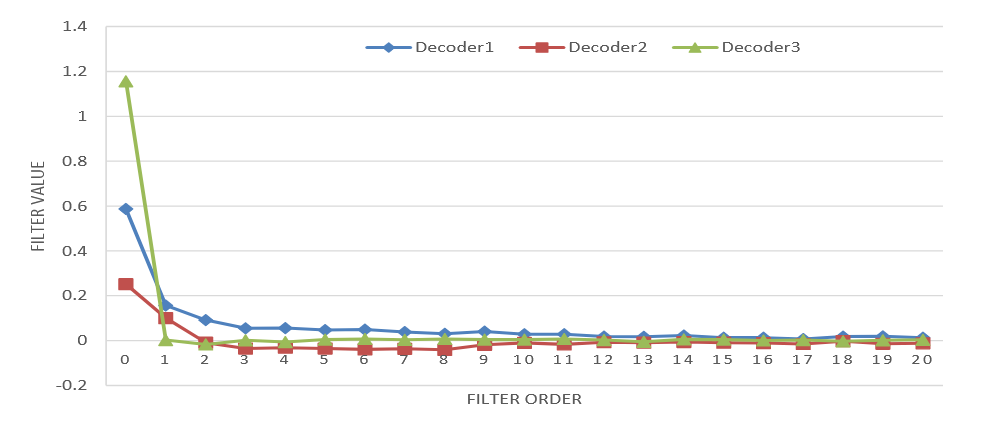
推理效率
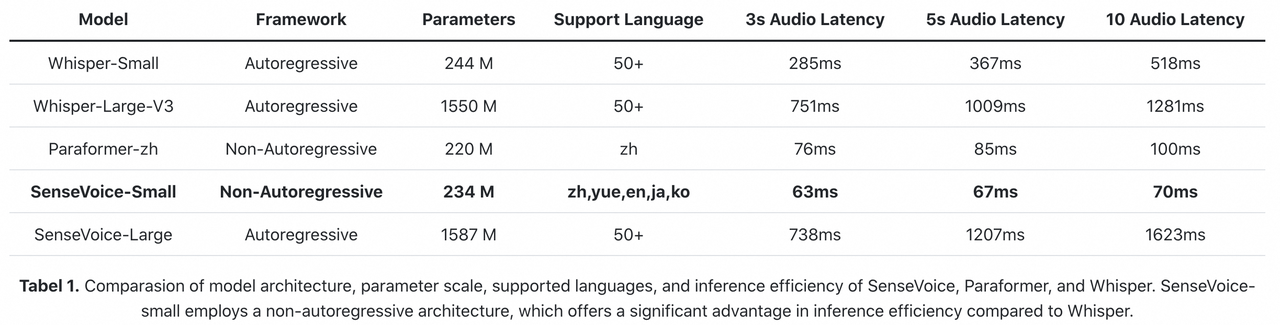
SenseVoice-Small模型采用非自回归端到端架构,推理延迟极低。在参数量与Whisper-Small模型相当的情况下,比Whisper-Small模型推理速度快7倍,比Whisper-Large模型快17倍。同时SenseVoice-small模型在音频时长增加的情况下,推理耗时也无明显增加。
总结
自注意力在编码器中对声学特征进行建模时,往往更多地受到短期依赖的影响,所以可能无法有效地捕捉到长期依赖关系。自注意力机制是具备强大的长期依赖建模和捕捉整个序列的长期依赖关系的能力。但单个 DFSMN 记忆块层主要对局部短期依赖进行建模,需要堆叠多层才能捕捉长期依赖。自注意力机制和 DFSMN 记忆块在一定程度上是互补的。
- 自注意力具备学习完整序列内长期依赖关系的能力,不过学习到的特征未必总是长期依赖的,特别是在编码器中;
- DFSMN 记忆块倾向于学习局部依赖关系,而且它们比自注意力的计算效率更高、更灵活;
- 自注意力学习着眼于单个特征的长期上下文依赖,而 DFSMN 记忆块则是从整个数据集的统计平均分布中学习局部依赖关系,这或许会让其在实际应用中更为稳健 。