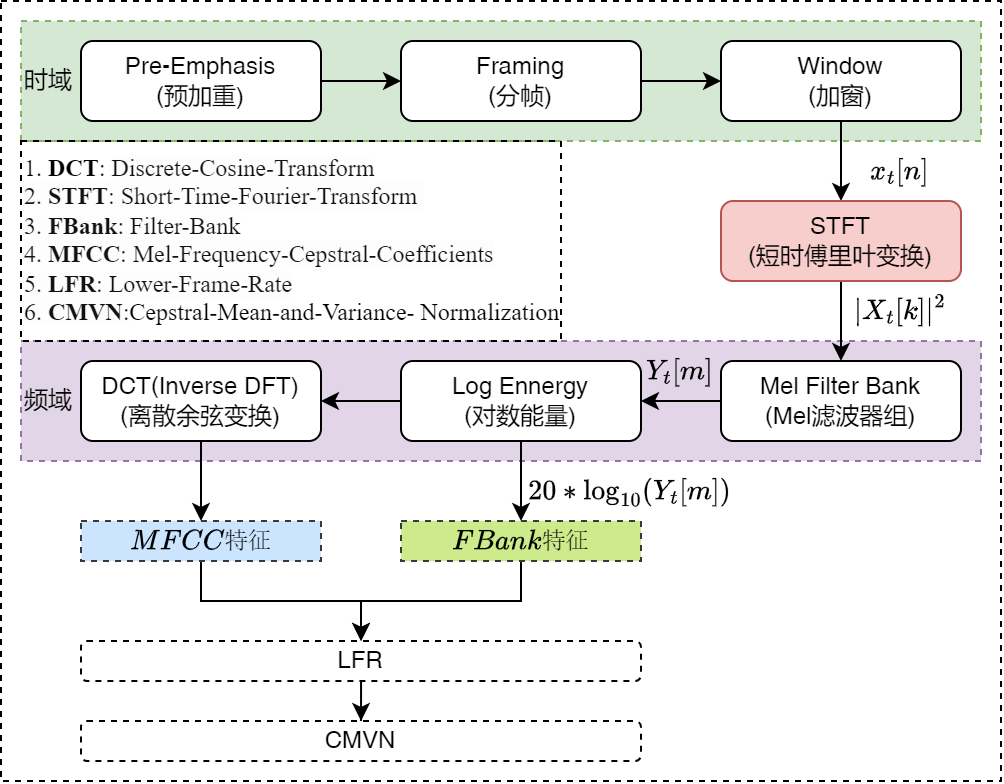
音频处理前处理算法汇总
概述
语音模型常用的语音特征类型如下:
- 梅尔滤波器组系数(Mel Filter Bank, FBank, 又称 Log-Mel);
- 梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC); 如下图所示,是提取上述特征的流程:
预加重(Pre-Emphasis)
预加重通常是数字语音信号处理的第一步,这是因为语音信号往往存在频谱倾斜(Spectral Tilt)现象。其主要原因在于,高频信号在空气中传播时衰减更为明显,致使高频部分的幅度要比低频部分小。在此,预加重扮演着平衡频谱的角色,用于增大高频部分的幅度。它通过如下的一阶滤波器来达成:
\[y(t)=x(t)-\alpha * x(t-1), 0.95<\alpha<0.99\]
上述等式通过Z变换,等效信号通过了一个高通滤波器:
\[H(z)=1-\alpha z^{-1}\]
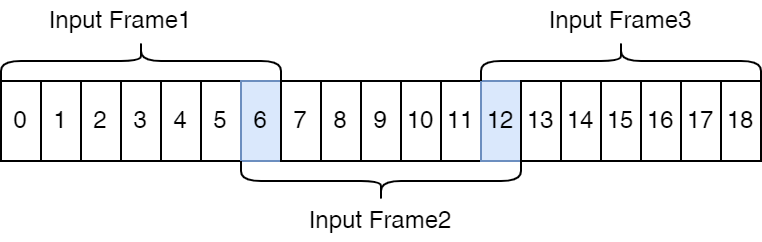
分帧(Framing)
我们已经知道采集到音频数据,是时间轴上的数据序列,声波随着之间变化在整个时间轴上是 非周期性 的,这导致计算机很难处理。 但在一个很短的时间切片内(10ms-50ms),声波是可以近似看为周期性的。所以我们可以把长序列数据切片,每片称为一帧。 对于ASR应用而言,通常取帧长为25ms,步长为10ms。
加窗(Window)
即使是周期信号,如果截断的时间长度不是周期的整数倍(周期截断),那么,截取后的信号将会存在泄漏。加窗主要是为了使时域信号似乎更好地满足FFT处理的周期性要求,减少泄漏。
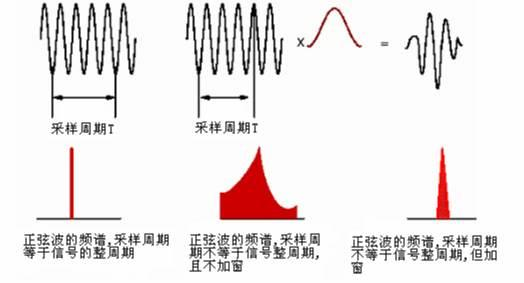
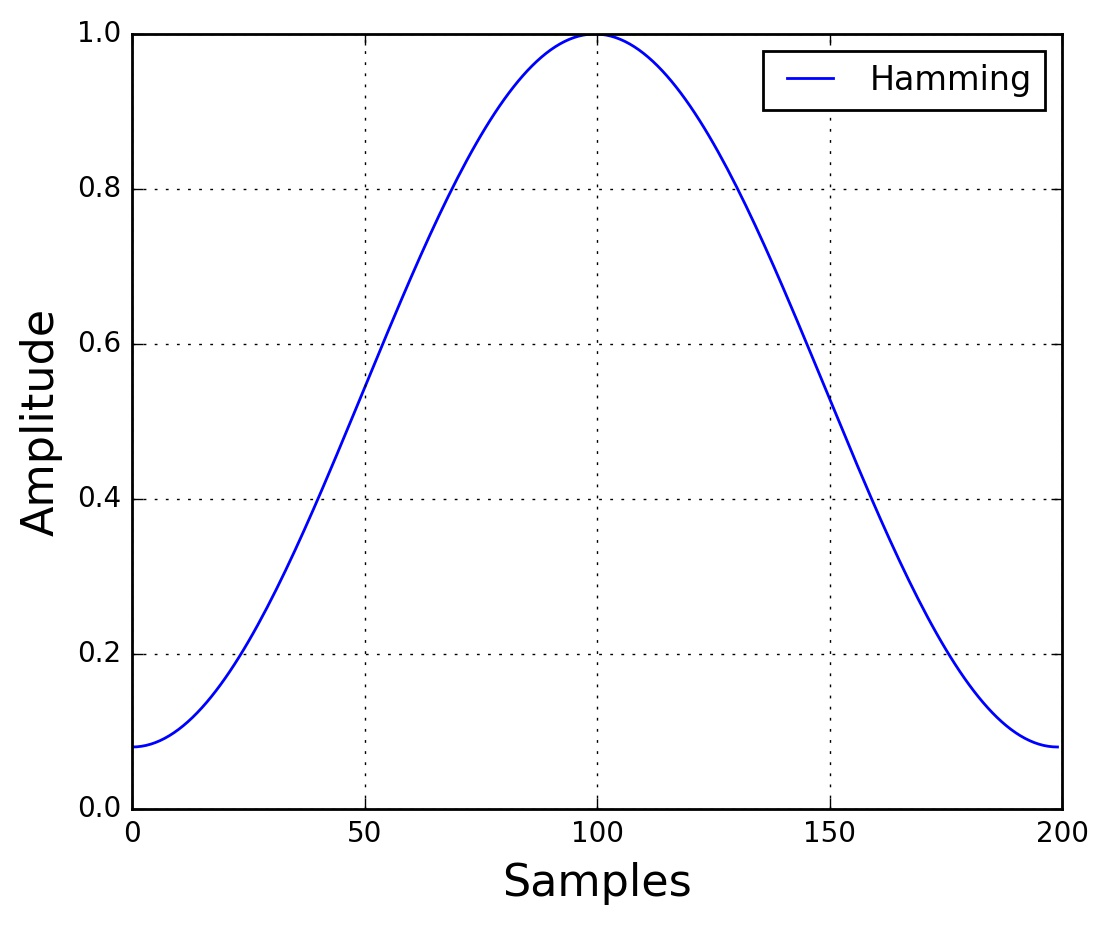
在分帧之后,通常需要对每帧的信号进行加窗处理。目的是让帧两端平滑地衰减,这样可以降低后续傅里叶变换后旁瓣的强度,取得更高质量的频谱。常用的窗有:矩形窗、汉明(Hamming)窗、汉宁窗(Hanning)。 锥形窗函数可表示为
\[w(n)=(1-\alpha)-\alpha \cos(\frac{2\pi n}{N-1})\]
其中, \(N\)表示窗的宽度, \(0 \le n \le N-1\)。
- 汉明窗: \(\alpha=0.46164\)
- 汉宁窗: \(\alpha=0.5\) 下图是经过汉明窗处理后的信号:
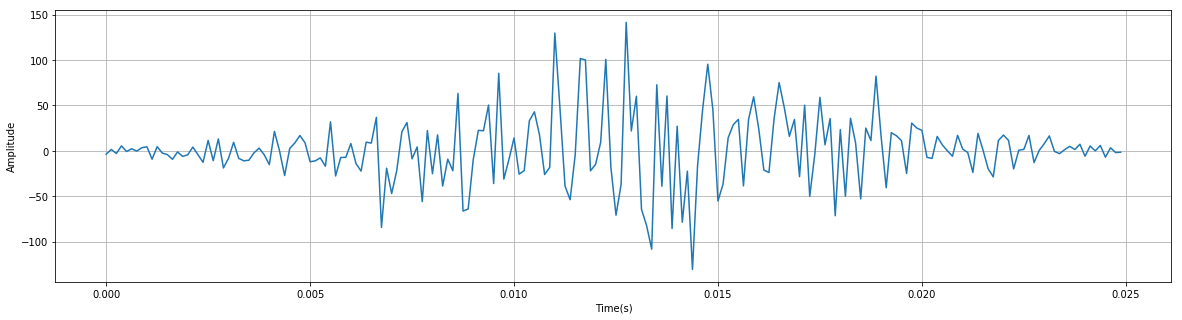
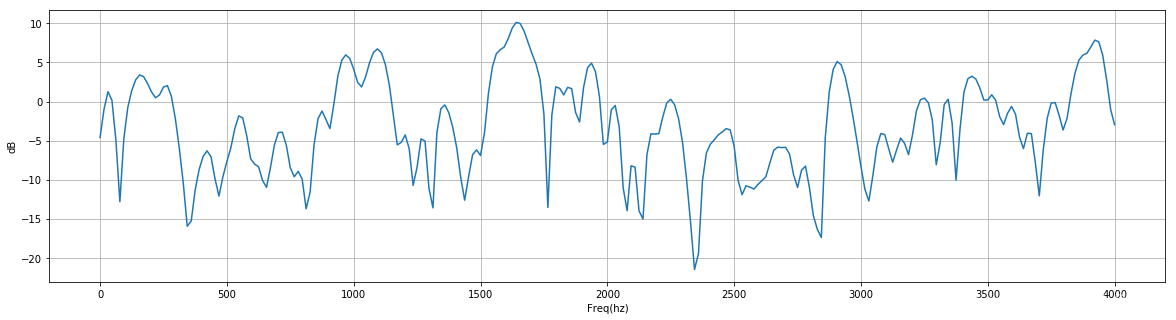
快速傅里叶变换(FFT)
对于每一帧的加窗信号,进行N点FFT变换,也称短时傅里叶变换(STFT),N通常取256或512,然后用如下的公式计算能量谱: \[P=\frac{|FFT(x_i)|^2}{N}\] 其中, \(x_i\) 表示信号 \(x\) 的第 \(i\) 帧。
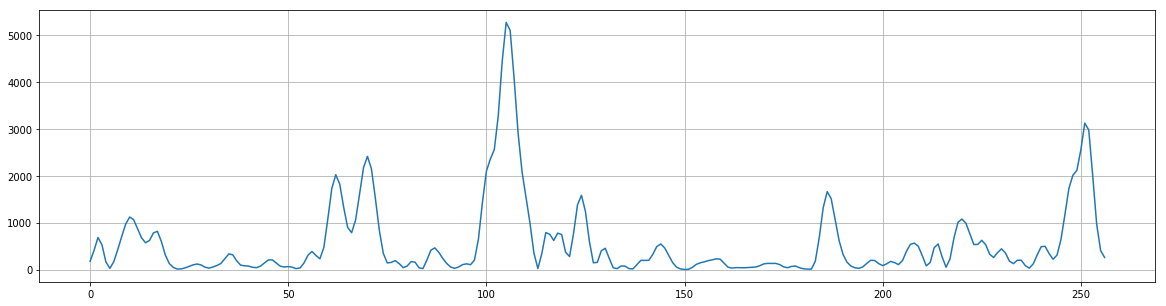
FBank特征(Filter Banks)
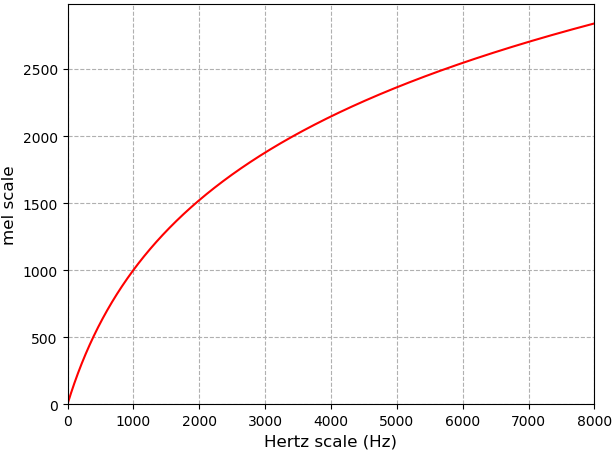
经过上面的步骤之后,在能量谱上应用Mel滤波器组,就能提取到FBank特征。在介绍Mel滤波器组之前,先介绍一下Mel刻度,这是一个能模拟人耳接收声音规律的刻度,人耳在接收声音时呈现非线性状态,对高频的更不敏感,因此Mel刻度在低频区分辨度较高,在高频区分辨度较低,与频率之间的换算关系为:
\[m=2595\log_{10}(1+\frac{f}{700})\] \[f=700(10^{m/2595}-1)\]
Mel滤波器组就是一系列的三角形滤波器,通常有40个或80个,在中心频率点响应值为1,在两边的滤波器中心点衰减到0,如下图:
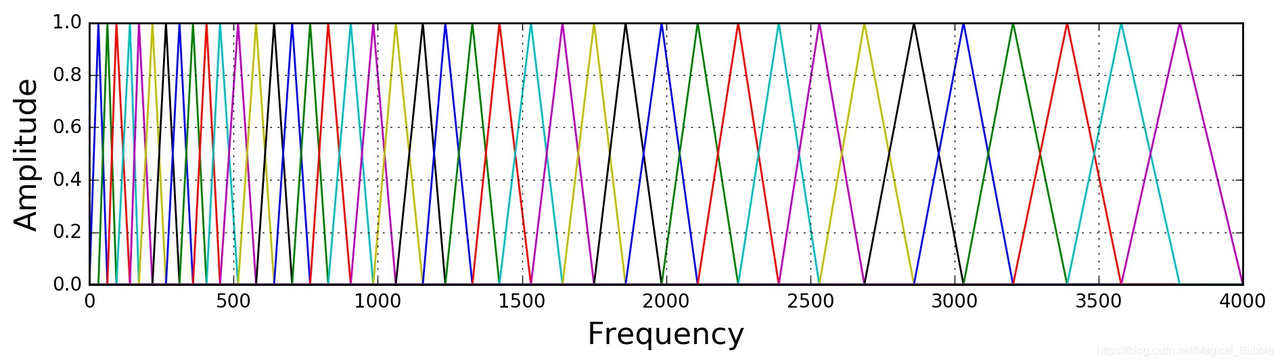
具体公式可以写为: \[\large H_{m}(k)= \begin{cases} 0 & k<f(m-1) \\ \frac{k-f(m-1)}{f(m)-f(m-1)} & f(m-1)\le k < f(m) \\ 1 & k=f(m) \\ \frac{f(m+1)-k}{f(m+1)-f(m)} & f(m)<k\le f(m+1) \\ 0 & k>f(m+1) \end{cases}\] 最后在能量谱上应用Mel滤波器组,其公式为: \[Y_{t}(m)=\sum_{k=1}^{N}H_m(k)|X_t(k)|^2\] 其中, \(k\) 表示FFT变换后的编号, \(m\) 表示mel滤波器的编号。
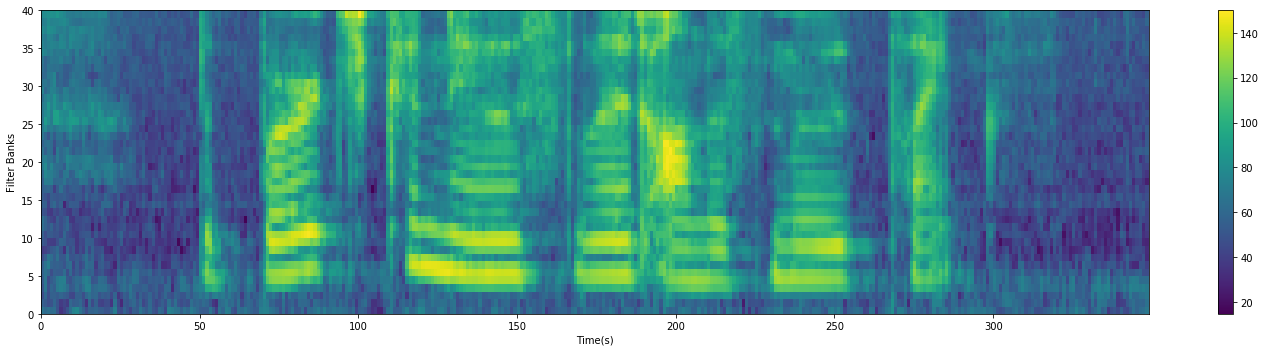
MFCC特征(Mel-frequency Cepstral Coefficients)
前面提取到的FBank特征,往往是高度相关的。因此可以继续用DCT变换,将这些相关的滤波器组系数进行压缩。对于ASR来说,通常取2~13维,扔掉的信息里面包含滤波器组系数快速变化部分,这些细节信息在ASR任务上可能没有帮助。 DCT变换其实是逆傅里叶变换的等价替代: \[y_t(n)=\sum_{m=0}^{M-1}\log(Y_t(m))\cos(n(m+0.5)\frac{\pi}{M}), n=0,...,J\] 所以MFCC名字里面有倒谱(Cepstral)。 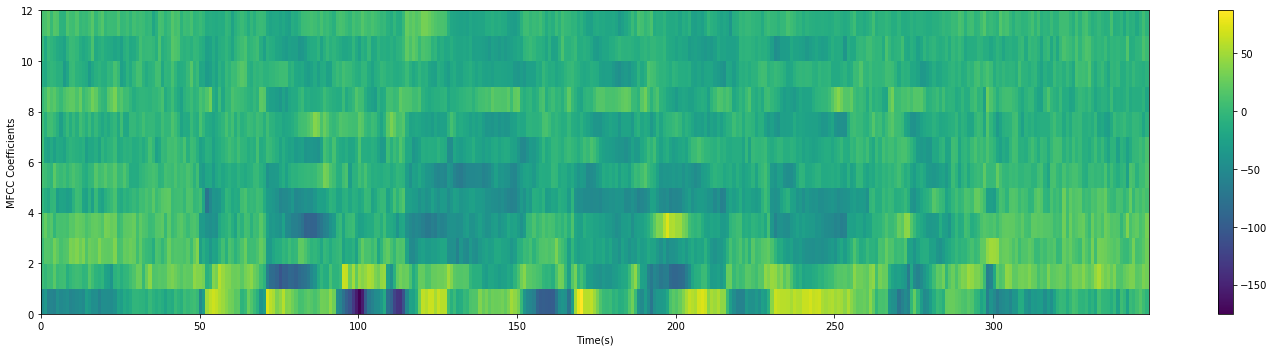
FBank和MFCC比较
FBank特征的提取更多的是希望符合声音信号的本质,拟合人耳接收的特性。而MFCC特征多的那一步则是受限于一些机器学习算法。很早之前MFCC特征和GMMs-HMMs等机器学习方法结合是ASR的主流。而当一些深度学习方法出来之后,MFCC则不一定是最优选择,因为神经网络对高度相关的信息不敏感,而且DCT变换是线性的,会丢失语音信号中原本的一些非线性成分。 还有一些说法是在质疑傅里叶变换的使用,因为傅里叶变换也是线性的。因此也有很多方法,设计模型直接从原始的音频信号中提取特征,但这种方法会增加模型的复杂度,而且本身傅里叶变换不太容易拟合。同时傅里叶变换是在短时上应用的,可以建设信号在这个短的时间内是静止的,因此傅里叶变换的线性也不会造成很严重的问题。 结论就是:在模型对高相关的信号不敏感时(比如神经网络),可以用FBank特征;在模型对高相关的信号敏感时(比如GMMs-HMMs),需要用MFCC特征。从目前的趋势来看,因为神经网络的逐步发展,FBank特征越来越流行。
标准化
- 去均值 (CMN)
为了均衡频谱,提升信噪比,可以做一个去均值的操作。
- 方差归一 (CVN)
除以标准差,从而使得方差为1。
- 标准化 (CMVN)
\[\tilde{y}_t = \frac{y_t-\mu(y)}{\sigma(y)}\]
LFR
LFR(低帧率)是语音识别声学建模中使用的一种技术,用于降低训练和解码的计算成本和内存占用。它通过将多个连续的特征帧堆叠在一起作为输入,去预测这些语音帧的目标输出得到的一个平均输出目标。