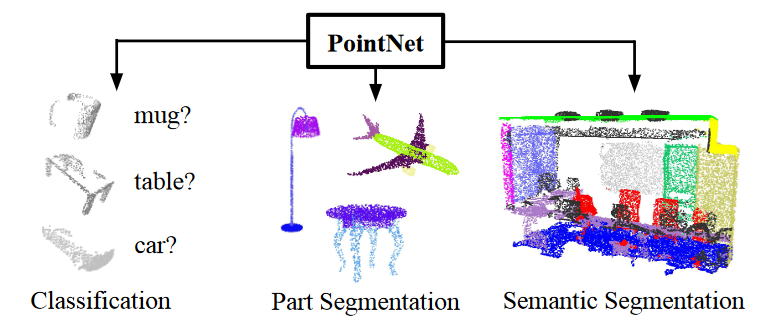
PointNet模型分析(3D对象检测)

理论分析
点云存在两个问题
无序性
点云是一组无序的向量,其中点的不同排序,结果应该一致。 
如何解决?
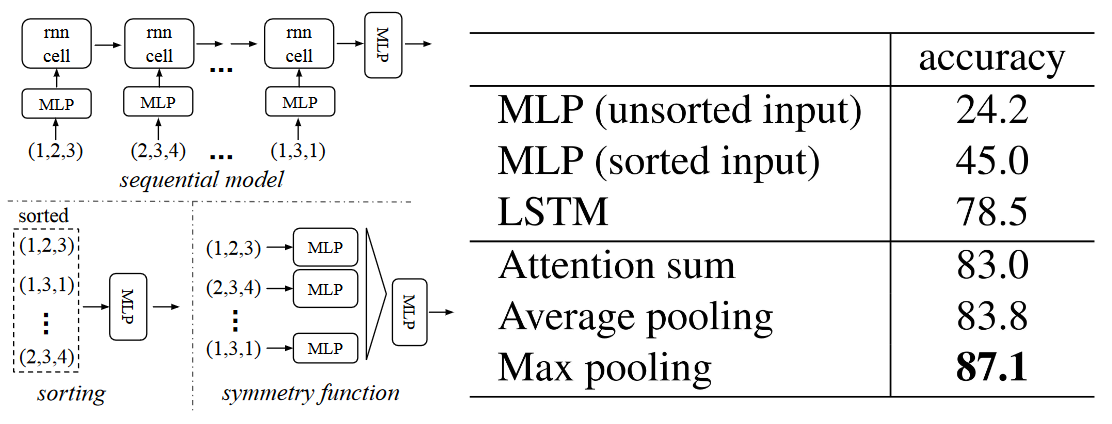
- 方式一:按照一定规则对点集进行排序;
- 方式二:将点集的所有排列作为增强数据,训练一个循环网络;
- 方式三:利用一个对称函数将所有信息进行聚合; 其中, 方式一看似简单,但是在高维空间中,实际上不存在一个在一般意义上相对于点扰动稳定的排序方式。 方式二被证明对于长度小的序列(几十个)有较好的鲁棒性,但对于动不动上千的点云数据不太合适。 因此,PointNet采用方式三,具体三种方式的精度对比如下:
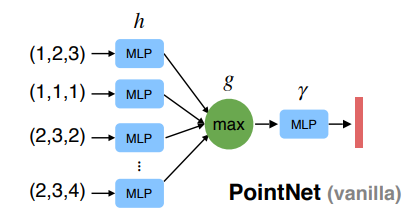
文章的主要思想是对集合中的变换元素应用对称函数来近似定义在点集上的通用函数: \[f({x_1,...,x_n})\approx g(h(x_1),...,h(x_n))\] 其中,\(h\)函数使用 MLP 网络近似,\(g\)函数使用 单变量函数与 MaxPool 函数的组合。
常见的对称函数有:
- 求和函数 \[g(x_1,x_2,...,x_n) = x_1 + x_2 + ... + x_n\]
- 求最大值函数 \[g(x_1,x_2,...,x_n) = \max \{ x_1,x_2,...,x_n \}\] 通过一系列的\(h\)函数可以捕获点集合的不同属性(3D结构特征等) 故 PointNet 选择采用多层感知机(MLP)和最大池化(MaxPool)算子构建网络框架。
旋转变换后分类结果一致
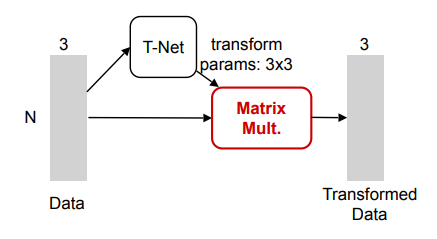
要做到旋转的一致性,PointNet引入T-Net得到一个旋转矩阵,对输入特征进行自动对齐。将正则化项添加到我们的softmax训练损失中,即将特征变换矩阵约束为接近正交矩阵(正交变换不会丢失输入中的信息)。
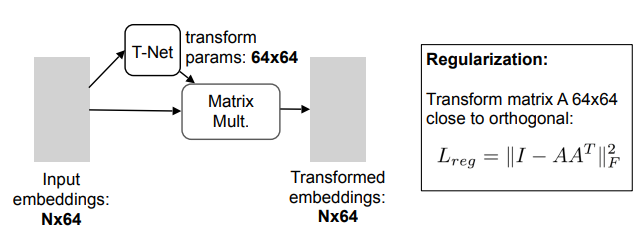
实验发现,通过添加正则化项,优化变得更加稳定,并且模型也获得了更好的性能。
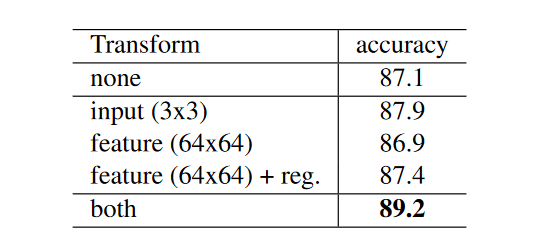
使用输入变换精度可以提升0.8%,而增加正则损失对高维度的变换是有效的。
鲁棒性好
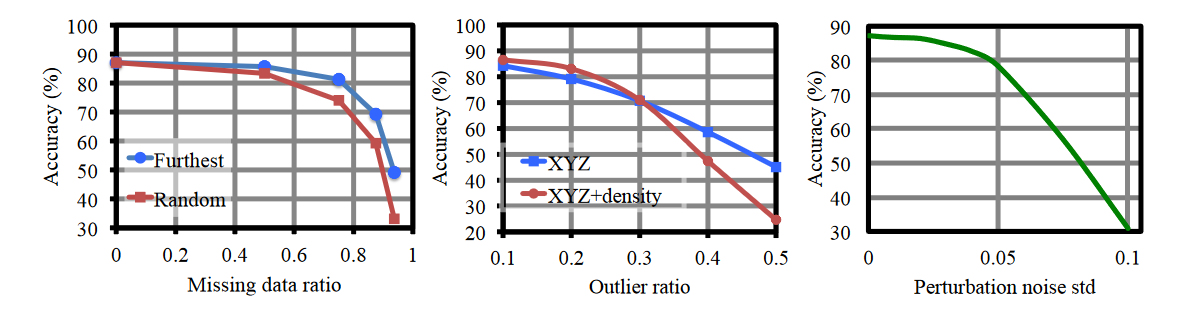
实验结果
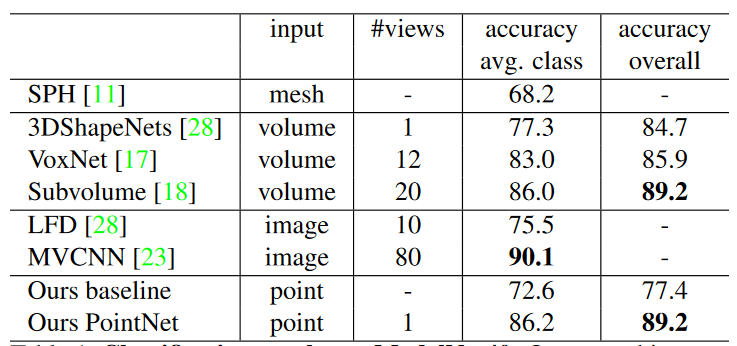

网络结构
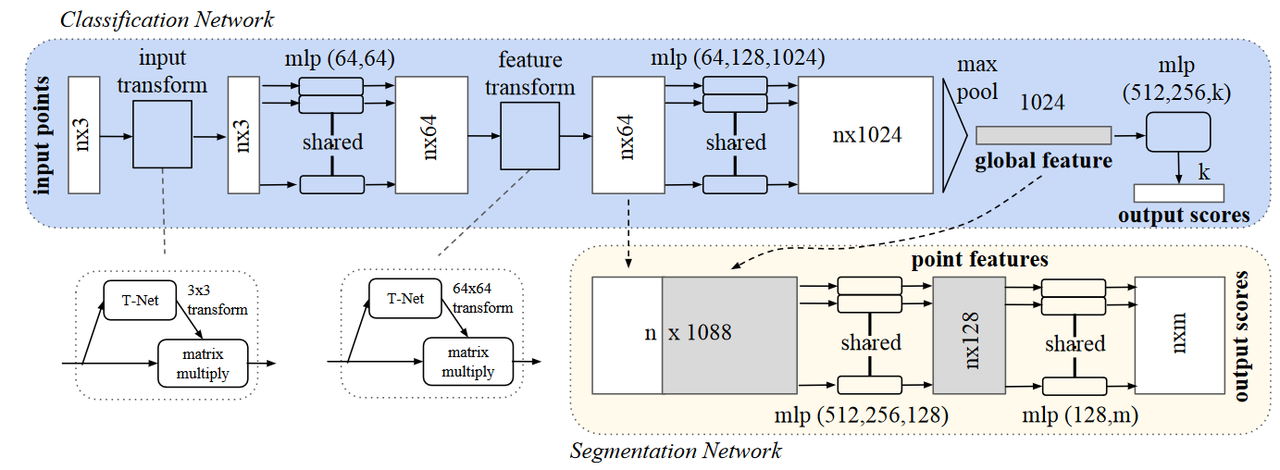
- 分类网路只使用global特征进行预测;
- 语义分割网络使用local和global特征进行预测;
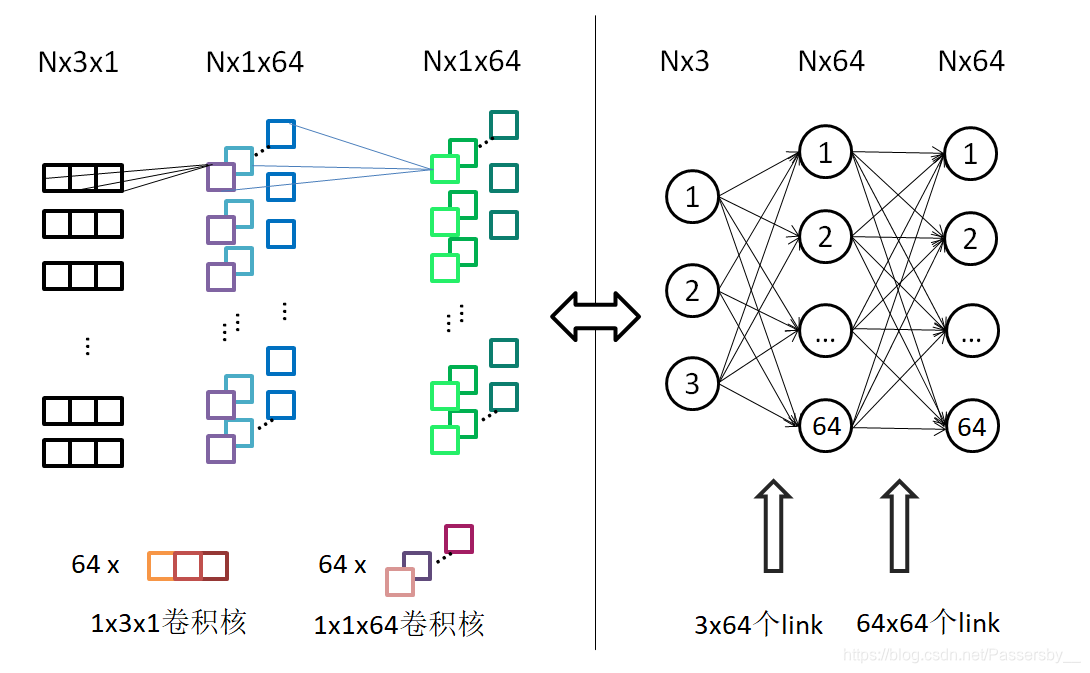
Share MLP
PointNet使用二维卷积网络来实现Shared MLP。
网络代码
1 | def get_model(point_cloud, is_training, bn_decay=None): |
T-Net
1 | def input_transform_net(point_cloud, is_training, bn_decay=None, K=3): |