基于LiDAR的3D对象检测综述
概述
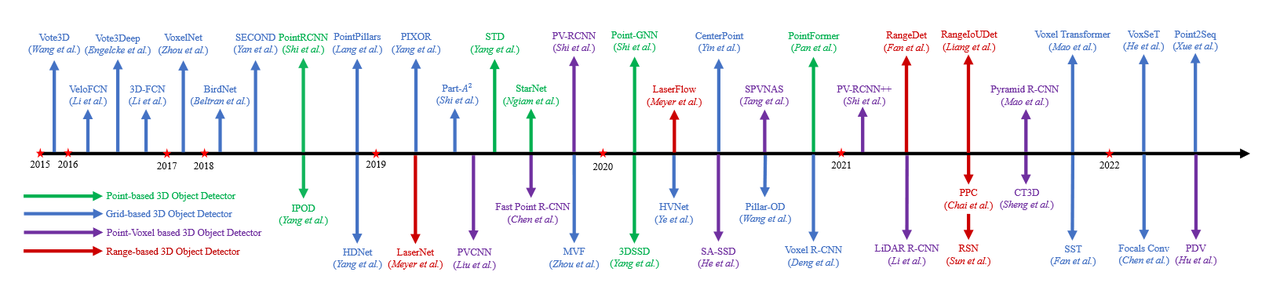
先进的3D对象检测方法提出了各种从稀疏的点云数据中学习辨别特征的方法:
- 将点云投影到鸟瞰图,并利用2D CNN学习点云特征以生成3D预测框;
- 将点云分组为体素,并使用3D CNN学习体素的特征来生成3D框;
- 直接采样点云数据,并使用MLP学习点云特征来生成3D框;

存在问题
- 鸟瞰图投影或体素化表示都会因为数据量化遭受信息丢失;
- 3D CNN的内存利用率和计算效率都很低;
3D对象检测的数据表示
- 与像素规则分布的图像相比,点云数据是稀疏且不规则的3D表示,需要特定设计的模型进行特征提取。
- 距离图像 是密集和紧凑的表示形式,但是距离图像包含3D信息而不是RGB通道数值。因此直接使用传统的卷积神经网络可能不是最优的解决方案。
基于点的对象检测器
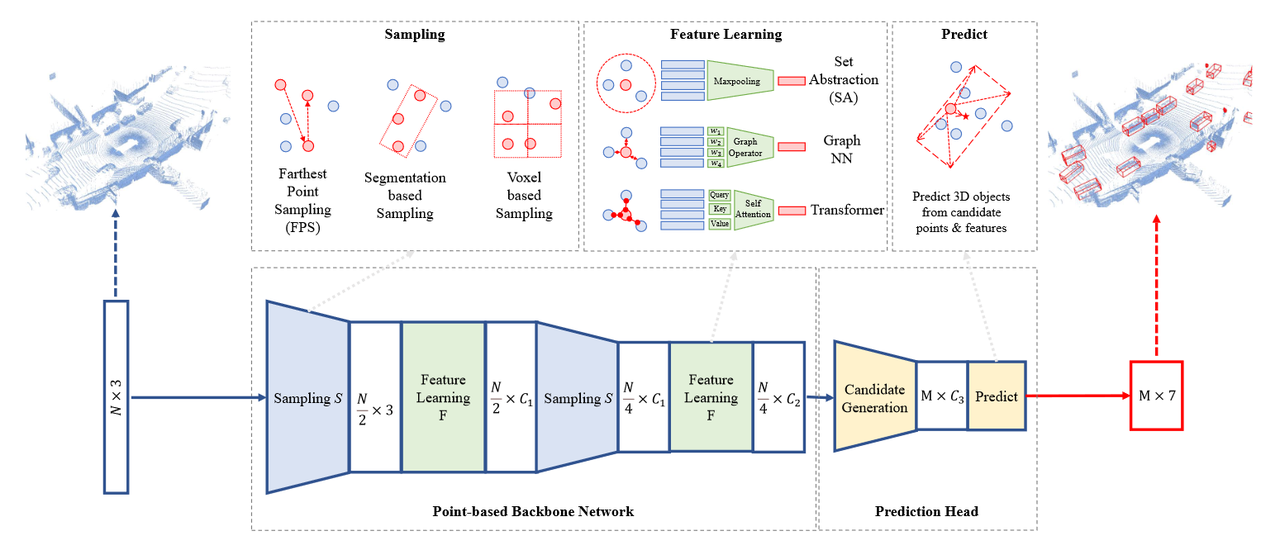
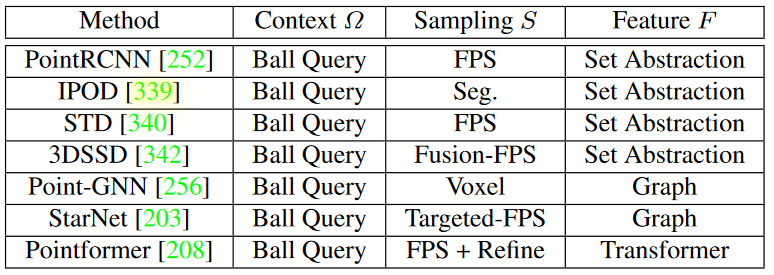
点采样算法
FPS(Farthest Point Sampling) or D-FPS(Distance-Farthest Point Sampling)
最远点采样在PointNet++网络中首次提出,并在基于点的检测器中被广泛采用,其基本思想如下: 给定一个输入点集\(\{x_1, x_2, ..., x_n\}\),使用FPS算法去选择输入点的子集 \(\{x_{i_1}, x_{i_2}, ..., x_{i_m}\}\)。
- 随机从\(\{x_1, x_2, ..., x_n\}\)中选择一个点\(x_{i_1}\);
- 从剩余的点集中查找与点\(x_{i_1}\)距离最远的点\(x_{i_2}\);
- 以此类推,从剩余的点集中查找与集合 \(\{x_{i_1}, x_{i_2}, ..., x_{i_{j-1}}\}\)中的点距离最远的点\(x_{i_j}\);

Segmentation Guided Filter
IPOD 模型中首次提出,基于语义的引导过滤采样。

选择正样本点
- 首先滤除背景点,采用2D语义分割网络预测前景像素,然后使用给定的相机矩阵将这些像素投影到点云中作为掩膜来收集正样本点。
- 基于这些正样本点的中心,生成具有多个尺度,角度和偏移的proposals,如下图,基于BEV视图,基于2种anchors生成6个proposals。这些proposal可以覆盖汽车对象的大部分关键点。
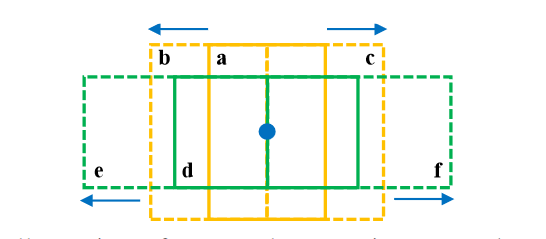
减少冗余的proposals
采用 non-maximum suppression (NMS) 去除多余的proposals,其中每个proposal的core值是其内部点的语义分割值之和,尽量选择包含更多点的proposal,IoU的值计算基于每个proposal在BEV视图下的投影。
减少歧义proposals
如下图所示,使用内部点的中心和预定义的特定类别的archor大小替换AB为C
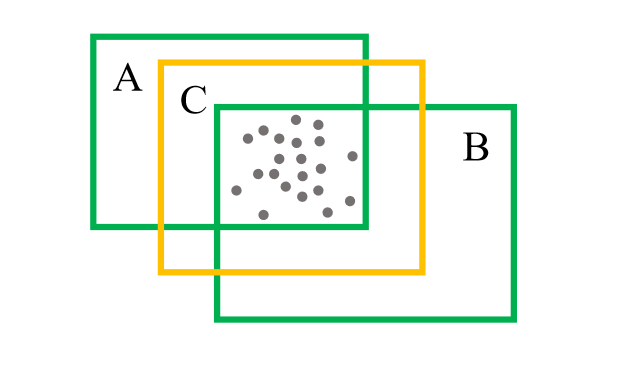
在训练期间,为proposal分配目标标签时存在一些歧义点。如果只考虑proposal和GT box的IoU值来标注正负标签,可能是不合适。
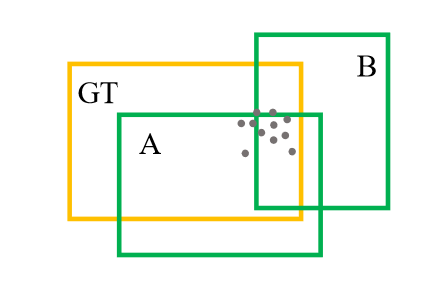
提出 PointsIoU ,通过计算两个Box交集的点数与并集的点数之商。
Fusion Sampling
- Feature-FPS 3DSSD模型中首次提出,其采用空间距离和语义特征距离作为FPS的标准 \[C(A,B) = \lambda L_d(A,B) + L_f(A,B)\] 其中, \(L_d(A,B)\)表示 \(L2\)(x,y,z)距离,\(L_f(A,B)\)表示 \(L2\)语义特征距离。
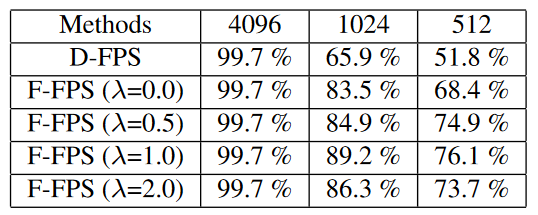
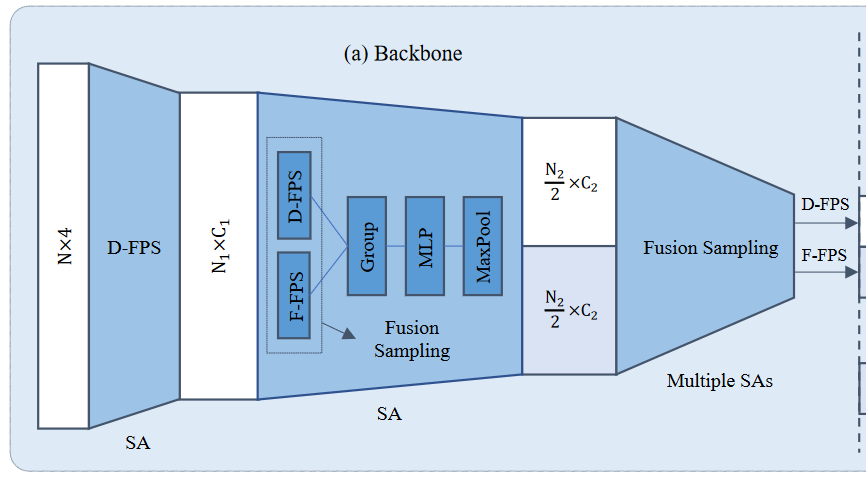
如上图所示,3DSSD是中提出的Fusion Sampling策略,即在SA层中同时应用 F-FPS 和 D-FPS,保留足够的正样本点用于位置定位,同时保留足够的负样本点用于分类任务。
Voxel-Base
基于体素的采样
Targeted-FPS
随机采样
FPS + Refine
坐标细化 特征提取算法
MLP+MaxPool
Graph NN
Transformer
总结
目前大多数的基于点的方法,点云采样是其推理时间的瓶颈,无法满足自动驾驶对实时性的要求。
参考
- 3D Object Detection for Autonomous Driving: A Comprehensive Survey