3D Object Detector Introduce
概述
在自动驾驶领域,感知系统是必不可少的模块,通常使用多模态数据(激光雷达的点云、摄像头的图片、高清地图等)作为输入,预测道路上关键元素的几何形状和语义信息,为目标跟踪、轨迹预测和路径规划模块提供可靠的观察结果。 为了全面了解行驶环境,涉及许多视觉任务,包括:对象检测、跟踪、车道线检测、语义分割和实例分割。其中,3D对象检测是自动驾驶感知系统最不可或缺的任务。 3D对象检测的目标:
- 位置:(x, y, z)
- 大小:(l, w , h)
- 朝向: (\(\theta\))
- 类别: (轿车、自行车、行人...)
相对于2D对象检测,其只在图像上生成边界框,而忽略物体与当前车辆的实际距离信息。3D对象检测重点关注于现实世界3维坐标系中的对象位置和识别。通过3D对象检测预测的几何信息可以直接测量当前车辆于关键对象之间的距离。

3D对象检测是什么?
简单讲就是从传感器数据中预测3D对象的边界框,使用简洁的数学公式表达通用的3D对象检测如下: \[\beta = f_{det}(\Gamma_{sensor})\] 其中
- \(\beta = \{B_1, B_2,...,B_N \}\):表示场景中 N 个 3D对象的集合;
- \(f_{det}\):表示3D对象检测模型;
- \(\Gamma_{sensor}\):表示一个或多个传感器的输入数据;
如何表示3D对象的边界框
通常3D对象被表示为包含该对象的3D长方体,即: \[B = [x_c,y_c,z_c,l,w,h,\theta,class]\] 其中,
- \([x_c,y_c,z_c]\):表示长方体的3D中心坐标;
- \([l,w,h]\):表示长方体的长、宽、高;
- \(\theta\): 表示航向角,即地平面上长方体的偏航角;
- \(class\):表示3D对象的类别,例如:汽车、自行车、行人...;
如何表示传感器输入
有许多类型传感器可以为3D对象检测提供原始数据,其中,激光雷达(LiDAR)、摄像头和毫米波雷达是三个最广泛使用的传感器类型。
3D毫米波雷达
优点
- 检测范围长;
- 适用不同的天气条件;
- 可提供额外的相对速度测量;
缺点
- 测量受物体散射影响;
- 静止目标和地物杂波混在一起,难以区分;
- 横穿车辆和行人多普勒为零或很低,难以检测;
- 高处物体和地面目标不能区分,容易造成误刹,影响安全性;
- 角度分辨率低,远处目标位置精度低,误差大;
- 点云稀疏,难以识别目标类型。
数据格式
\[[r,\theta,v] \to [x,y,v_x,v_y]\] 
4D毫米波雷达
优点
- 最远探测距离大幅提高,可达300多米,比激光雷达和视觉传感器都要远;
- 4D毫米波雷达水平角度分辨率较高,通常可以达到1°的角度分辨率;
- 4D毫米波雷达可以测量俯仰角度,可达到2°的角度分辨率,可在150m处区分地物和立交桥;
- 多普勒为零或很低的横穿车辆和行人, 通过高精度的水平角和俯仰角可以有效识别目标;
- 目标点云更密集,信息更丰富,更适合与深度学习框架结合。
数据格式
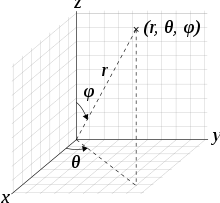
其中,图像中的每个像素在球坐标系中由径向距离(\(r\)), 方位角(\(\theta\)), 倾斜角(\(\varphi\))表示。
\([r,\theta,\varphi,v] \to [x,y,z,v_x,v_y]\)
摄像头
优点
- 价格便宜;
- 理解语义信息(红绿灯);
缺点
- 只能捕获外观信息;
- 不能够直接获取场景的3D结构信息,从图像估计的深度通常误差很大;
- 受极端天气(雾天,雨天)和时间(白天,晚上)的影响;
数据格式
\[\Gamma_{cam} \in R^{[w,h,3]} \] 其中,每个像素由 [red, green, blue] 组成。
激光雷达
优点
- 可以获得场景较高细粒度的3D结构信息;
- 不易受天气和时间的影响;
缺点
- 价格贵;
- 机械式的寿命短;
数据格式
距离图像
在一个扫描周期内,一次发射m一束光束,进行n次测量,可以生成如下距离图像。 \[\Gamma_{range} \in R^{[m,n,3]} \]
其中,图像中的每个像素在球坐标系中由径向距离(\(r\)), 方位角(\(\theta\)), 倾斜角(\(\varphi\))表示。
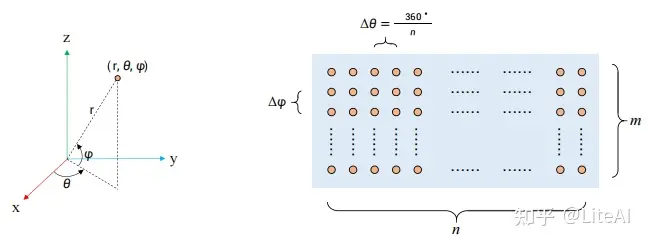
点云数据
点云数据可以由球坐标系转笛卡尔坐标系。 \[[r,\theta,\varphi] \to [x,y,z]\] 点云可以表示为 \[\Gamma_{point} \in R^{[N,3]} \] 其中,\(N\)表示场景中点数,每个点包含$[x,y,z]$3个坐标通道。

传感器数据汇总
如下图所示,自动驾驶车辆可以融合多类型传感器数据,输入3D对象检测网络,检测网络负责预测3D边界框。 
对比2D对象检测
3D对象检测借鉴了许多2D领域的设计范式:
- Anchors: 一组预定义的框;
- NMS: 非极大值抑制;
- ROI: 生成一组可能包含目标物体的候选区域;
- Refinement: 预测阶段对粗略的检测结果进行进一步的优化和提升的过程,例如,特征融合、残差网络、注意力机制等;
但是,从很多方面来讲,3D检测并不是2D检测方法对3D空间的简单适配,存在有如下特征:
- 数据表示多样性 3D检测必须处理异构的数据表示(点云、图像、距离图像等),对于点云输入的检测网络需要采用新型算子和网络来处理不规则的点数据,混合点云和图像数据的检测网络需要采用特殊的融合机制(前融合,特征融合、后融合)。
- 视角的多样性 3D对象检测网络通常利用不同的投影试图来生成对象预测,与从透视图(近大远小)中检测对象的2D对象检测方法相反,3D对象检测必须考虑不同的试图来检测3D对象,例如鸟瞰图、点视图、圆柱视图。
- 精度要求高 3D对象检测对3D空间中的对象精准定位有着更高的要求,分米级的定位误差可能会导致行人和自行车等小物体的检测失败,而2D对象检测几个像素的定位误差仍能保持较高的IoU。
对比室内场景
- 点云分布不同 室内场景点云在扫描表面分布更均匀,点数更多,对于自动驾驶场景,大多数点落在传感器附近,远处的3D对象只能扫描到几个点;
- 计算实时性 自动驾驶场景下感知必须是实时的,以避免发生事故。因此所采用的算法必须计算高效,否则无法实际应用。