算法优化-1bit转8bit-NEON处理
概述
使用IVE可以加速sobel滤波器和canny滤波器,但是IVE生成的滤波器结果格式不满足实际需求。为此,需要通过软件方式将IVE的输出结果转化成需要的形式,可以使用c语言、NEON Intrinscis和NEON汇编等方式去实现。

Sobel滤波
Sobel滤波器的结果形式如下,使用16比特存储x和y方向的梯度值,其中低8位表示x轴方向梯度,高8位表示y轴方向梯度。
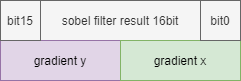
实际需求要将x和y方向的梯度拆分为两个字节,具体形式如下:
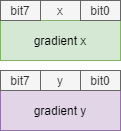
NfsU16ToU8WithTwo函数实现
该函数实现将16bit的高低位拆分为两个独立的字节,并将拆分后的字节单独输出。
C语言代码
使用C语言编写代码如下:
1 | for (int32_t i = 0; i < IMG_BUF_SIZE; i++) |
Running Time : 14.3ms
NfsU16ToU8Square 函数实现
该函数实现将16bit的高低位拆分为两个独立的字节(x,y),并计算\(x^2 + y^2\),将x和y轴的梯度求平方和后按照16bit输出结果。
C语言代码
使用C语言编写代码如下:
1 | uint8_t temp_x, temp_y; |
Running Time : 18.2ms
Intrinsics优化
首先想到的优化方式是采用NEON Intrinsics方式对上述C语言代码进行重构,该方式相比于编写汇编代码更加简单,且便于移植。
1 | int32_t i = 0; |
Running Time : 3.42ms
数据加载优化
随着对NEON指令集理解的深入,可以直接使用VLD2指令直接在加载数据时就实现x和y通道的拆分,从而进一步提升了处理的速度。
1 | int32_t i = 0; |
通过该方式,处理器时可以减少一次mov操作和一次shift操作。如下图所示,VLD2.8直接加载sobel_x进D8,同时加载sobel_y进D9。
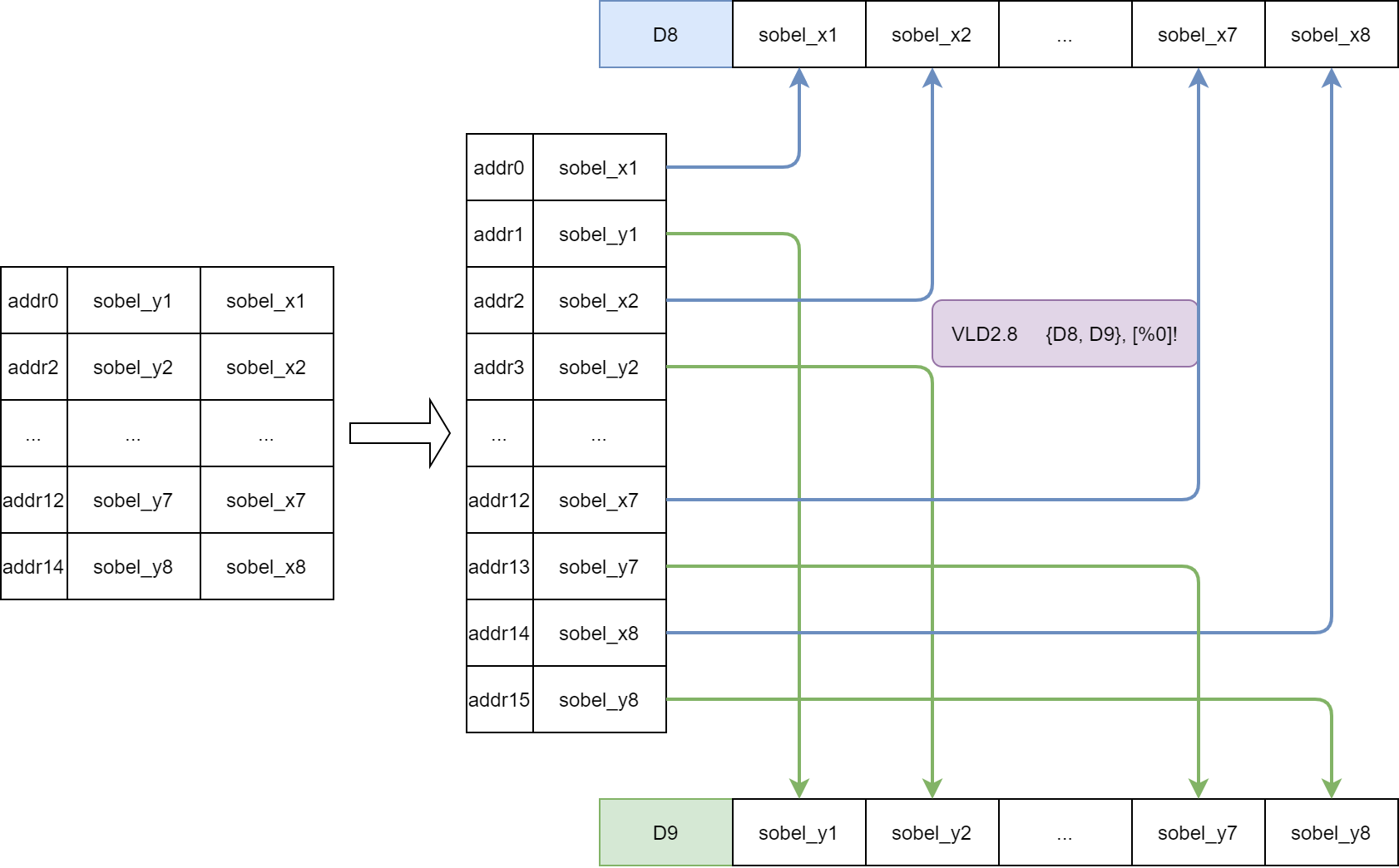
Running Time: 2.64ms
使能向量优化
在使用NEON Intinsics时,编译选项中需要使能向量化,具体编译参数如下:
1 | gcc -mcpu=cortex-a9 -mfloat-abi=hard -ftree-vectorize -O2 |
Canny滤波
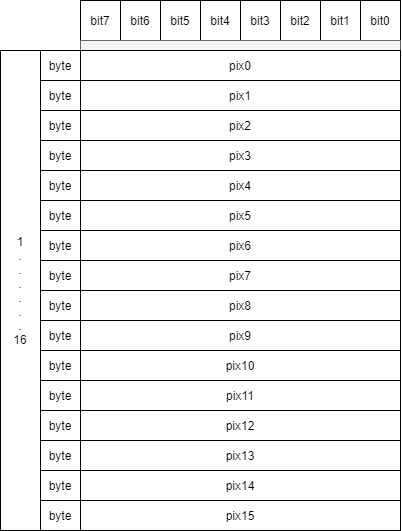
Canny滤波器的结果使用一个字节表示8个像素信息,具体形式如下:

因此,需要通过软件的方式将字节中的每一个bit像素拆分为一个字节表示,将上图中的两个字节数据进行转换,结果如下图所示:
NfsOneBitToU8函数实现
C语言代码
使用C语言编写代码如下:
1 | for (i = 0; i < IMG_BUF_SIZE; i++) |
汇编语言代码
算法思路
上述功能可以使用NEON汇编进行加速,具体思路如下:
- 加载操作 使用
VLD1指令从内存空间加载图像数据到Q6寄存器,该指令可以一次加载16个字节数据,对应图像的128个像素值;
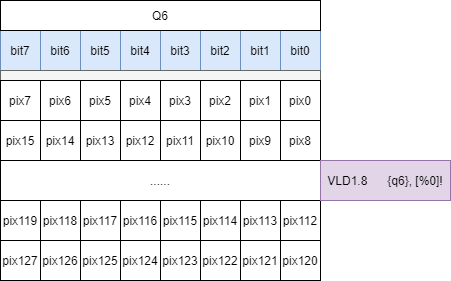
- 位与操作 使用
VAND指令,对Q6与Q4寄存器的元素进行位与操作,并将结果存入Q7寄存器,其中Q4寄存器可使用DUP指令全部置为0x01;此步骤将每个元素的低位像素值取出放入Q7寄存器中;
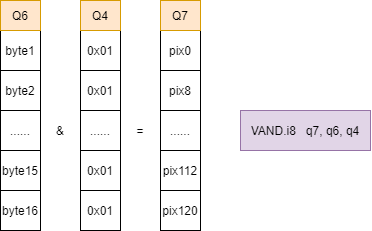
- 比较操作 使用
VCGT指令对Q7和Q5寄存器的元素逐个进行比较,判断Q7寄存器的元素是否大于对应Q5中的元素,其计算结果保存在Q8寄存器中。如果Q7的元素大于Q5的元素,则对应Q8元素设置为255,否则设置为0。
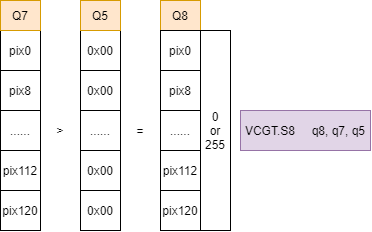
- 移位操作 使用
VSHR指令,将Q6中的元素整体向右移动1比特位,即将下一组像素移到元素最低位,方便循环取出图像像素值。
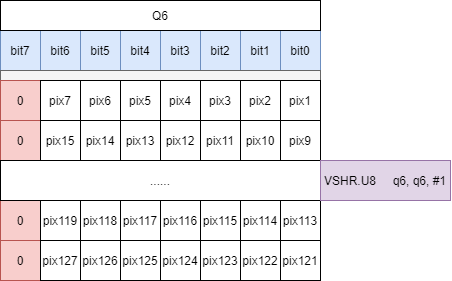
- 循环操作 循环上述2、3、4步骤,将
Q6寄存器中的像素值分别取出,放入Q8~Q15寄存器中。
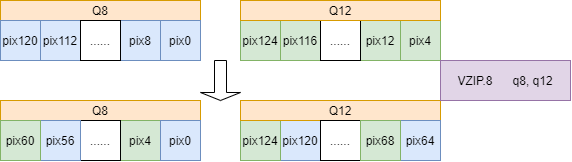
- 打包操作 使用
VZIP指令每隔4个Q寄存器进行一次打包操作,如下图所示,使像素索引号间隔4排列。该步骤的目的是未了方便下一步的存储操作。
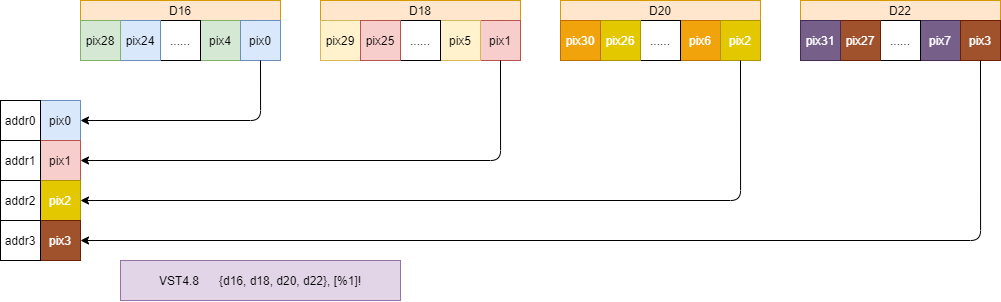
- 存储操作 使用
VST4指令将上述打包好的数据,按照像素循序存储相应的内存地址。
3.1.2.2 汇编代码
使用NEON Assembly编写上述功能代码如下:
1 | void NfsOneBitToU8Asm(uint8_t* restrict input, uint8_t* restrict output, uint32_t size) { |
性能对比
如下表所示,上述代码在联咏NT96565A平台运行时间如下:
| Function | C language | Intrinsics | Assembly |
|---|---|---|---|
| NfsU16ToU8WithTwo | 14.3 | 3.2 | 3.56 |
| NfsU16ToU8Square | 18.6 | 2.64 | 2.82 |
| NfsOneBitToU8 | 10.2 | 2.13 | 1.78 |