K-Quant
Overview
在llama.cpp中,常用的量化方式为 K-Quant ,这是一种混合量化方式,即不同的模型类型和权重位置会采用不同的量化位宽。其核心思想是,对于对模型精度影响较大的权重,采用更高的量化位宽。本节重点探讨了其量化算法背后的数学原理,旨在从数学角度深入理解其背后的数学原理。
K-Quant Compare
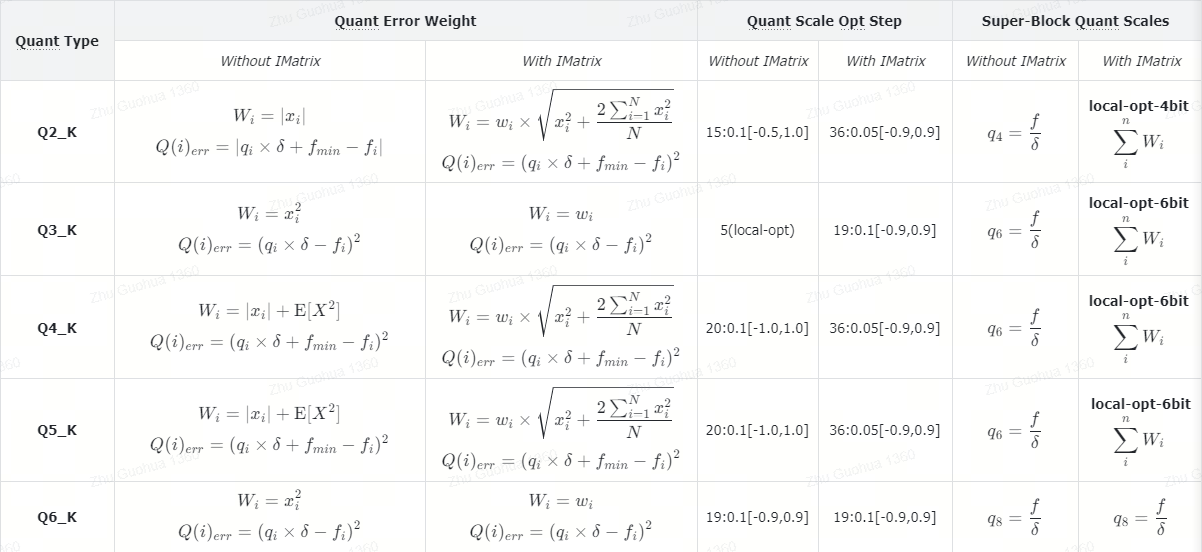
根据模型量化时是否使用IMatrix,K-Quant 算法会调用不同的实现,详细的对比如下:
在llama.cpp中,常用的量化方式为 K-Quant ,这是一种混合量化方式,即不同的模型类型和权重位置会采用不同的量化位宽。其核心思想是,对于对模型精度影响较大的权重,采用更高的量化位宽。本节重点探讨了其量化算法背后的数学原理,旨在从数学角度深入理解其背后的数学原理。
根据模型量化时是否使用IMatrix,K-Quant 算法会调用不同的实现,详细的对比如下:
llama.cpp中的KV Cache管理主要涉及Buffer的分配和管理。其中,Buffer采用静态分配的方式,初始时分配上下文大小的Buffer。当序列长度超出设定的上下文时,一种方式通过删除位置相对较远的KV Cache来释放一部分Cache空间,只保留相对较新的KV Cache;另一种是在模型上下文固定的情况下,通过压缩位置嵌入位置信息,实现更长上下文的支持。
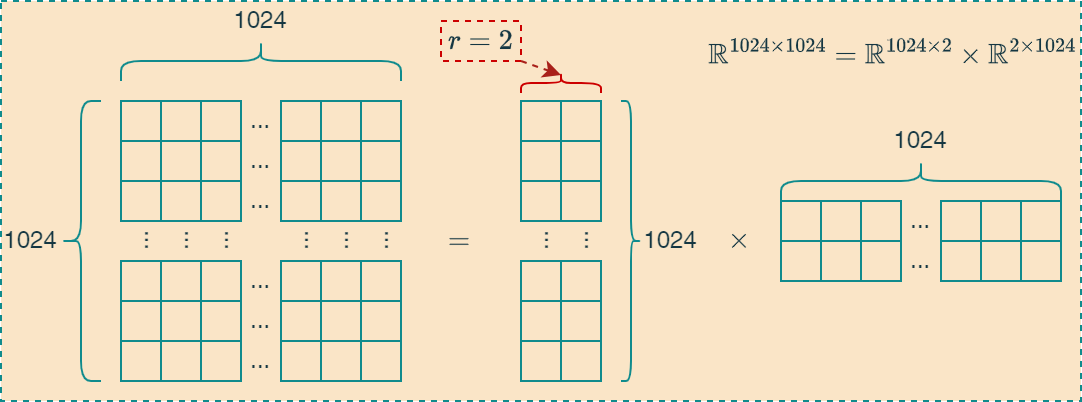
LoRA(Low-Rank Adaption)是微软研究人员2021年提出的一种高效的微调技术,其核心思想就是将大的矩阵分解为两个低秩矩阵表示,从而减少了权重的数据量。如下图所示,将矩阵 \(\Bbb{R}^{1024\times 1024}\)表示为两个低秩矩阵 \(\Bbb{R}^{1024\times 2}\)和 \(\Bbb{R}^{2\times 1024}\)相乘,其中秩的大小为2,可以减少256倍的数据体积。
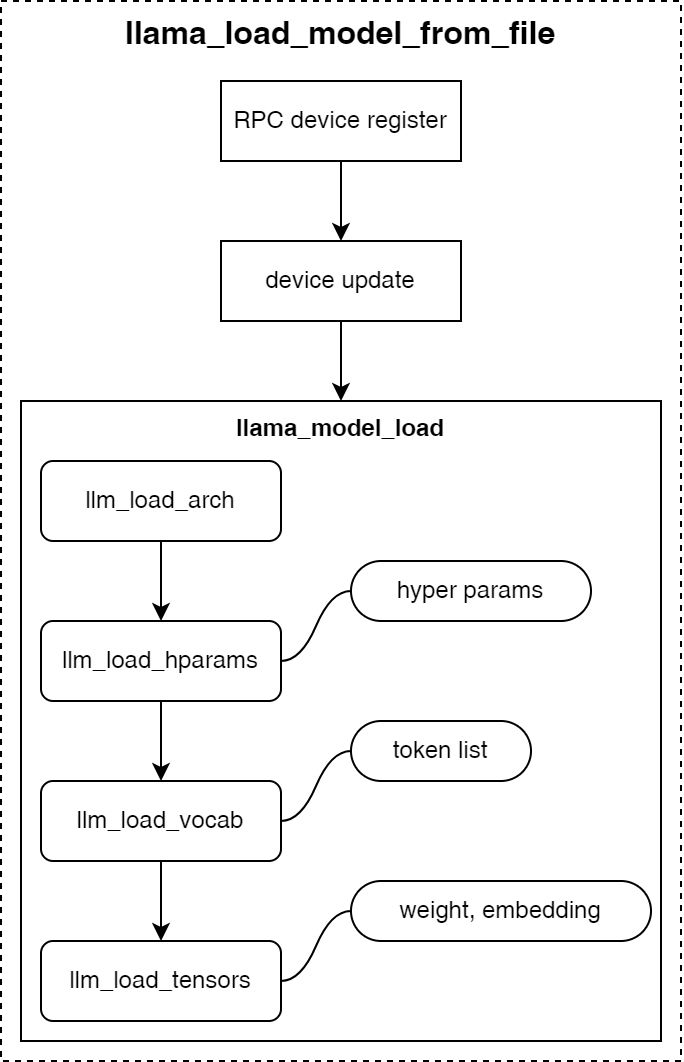
如下图所示,是llama.cpp加载GGUF格式模型文件时的调用流程:
llama.cpp 使用 ggml 张量加速库,这是一个纯 C++ 实现的张量加速库。
LLM的原始输出是一个 logits 列表,该列表中的每个元素对应一个词元的预测概率,基于它们选择下一个预测的token, 这个过程称为采样。目前llama.cpp存在多种采样方法可供选择,它们适用于不同的应用场景。 例如,在一些自然语言处理任务中,可能会采用贪心采样(Greedy Sampling)方法,即总是选择具有最高概率的token作为下一个 token。 这种方法简单直接,但可能会导致生成的文本缺乏多样性。 另一种常见的采样方法是随机采样(Random Sampling),它会根据 token 的概率分布进行随机选择。虽然这种方法增加了生成文本的多样性, 但也可能引入一些不太合理的选择。 为了在多样性和合理性之间取得平衡,还有一些更复杂的采样方法,如基于温度的采样(Temperature-based Sampling)。通过调整温度参数, 可以控制概率分布的平滑程度,从而影响采样的随机性。 此外,还有一些基于束搜索(Beam Search)的采样方法,它会同时考虑多个可能的序列,并根据一定的评估标准选择最优的序列作为输出。 不同的采样方法在不同的场景下具有各自的优势和局限性,选择合适的采样方法对于生成高质量的文本至关重要。
MiniCPM 是面壁与清华大学自然语言处理实验室共同开源的系列端侧大语言模型,主体语言模型 MiniCPM-1B 仅有 12亿(1.2B)的非词嵌入参数量。
如下图所示,是MiniCPMV模型的多模态推理流程图。如果有图片输入,会在文本字段中添加 (<image>./</image>)占位符号,表示需要基于该图片特征进行内容的生成,当然也可以支持多个图片的输入,简单示例如下:
1 | (<image>./</image>)What is this picture? |
1 | (<image>./</image>)(<image>./</image>)What is those pictures? |
那么从图片的像素特征空间转到语言模型特征空间后,其等效的文本token长度固定为64,多张图片的token长度则对应为64的倍数。

CTC,全称是Connectionist Temporal Classification,中文译为连接时序分类。特别适用于处理序列数据,例如语音识别、手写识别和机器翻译等任务,其中输入序列和输出序列的长度可能不一致。 更具体地说,CTC 解决了序列标注问题中标签与输入长度不匹配的难题。传统的序列标注方法要求输入序列和输出序列长度一致,而 CTC 允许输出序列比输入序列短,并引入了空白符(blank symbol)来处理重复和不必要的标签。
目前板端部署的语音模型是通义千问的SenseVoice Small模型,具有如下优点:
在语音特征前添加四个嵌入作为输入传递给编码器:
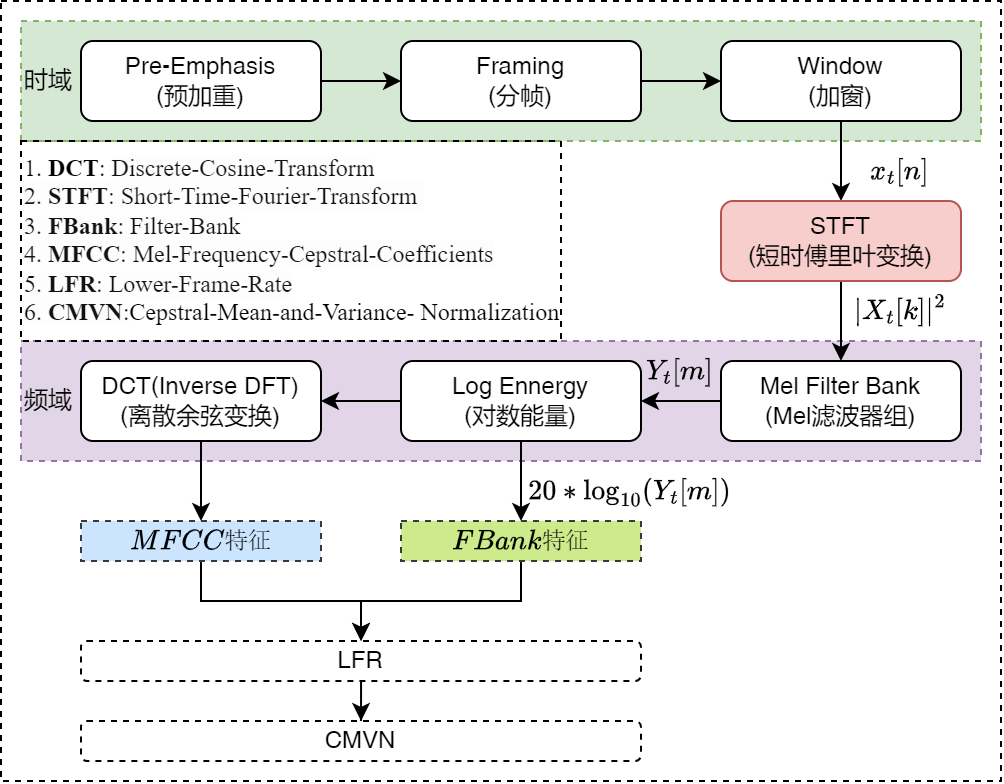
语音模型常用的语音特征类型如下: